Imagina a cena. Você acabou de entrar como engenheiro num banco digital ou numa empresa de cobrança. O time mostra um sistema que gera boletos em PDF, salva em algum lugar e disponibiliza um link para o cliente baixar. Parece simples. E é justamente aí que mora o perigo, porque esse "simples" começa a virar um problema na hora que aparecem dez mil clientes querendo baixar boleto ao mesmo tempo, ou quando alguém pergunta "tá, mas e se um atacante apagar tudo?", ou quando o time financeiro quer saber por que a fatura da nuvem dobrou em três meses.
O texto parte de uma versão zero desse backend em Java com Azure Blob Storage e vai adicionando camada por camada até uma arquitetura defensável. Cada conceito novo é explicado antes de ser usado: o que é, qual papel desempenha, e por que existe. Os erros que aparecem no caminho são tirados de incidentes documentados, com fontes verificáveis da Microsoft, da OWASP e de pesquisadores de segurança. Cada decisão carrega um trade-off explícito entre segurança, custo, operação e performance, e você termina o texto sabendo argumentar cada escolha, não só implementá-la.
Antes de tudo: por que não mandar o PDF como Base64 dentro do JSON
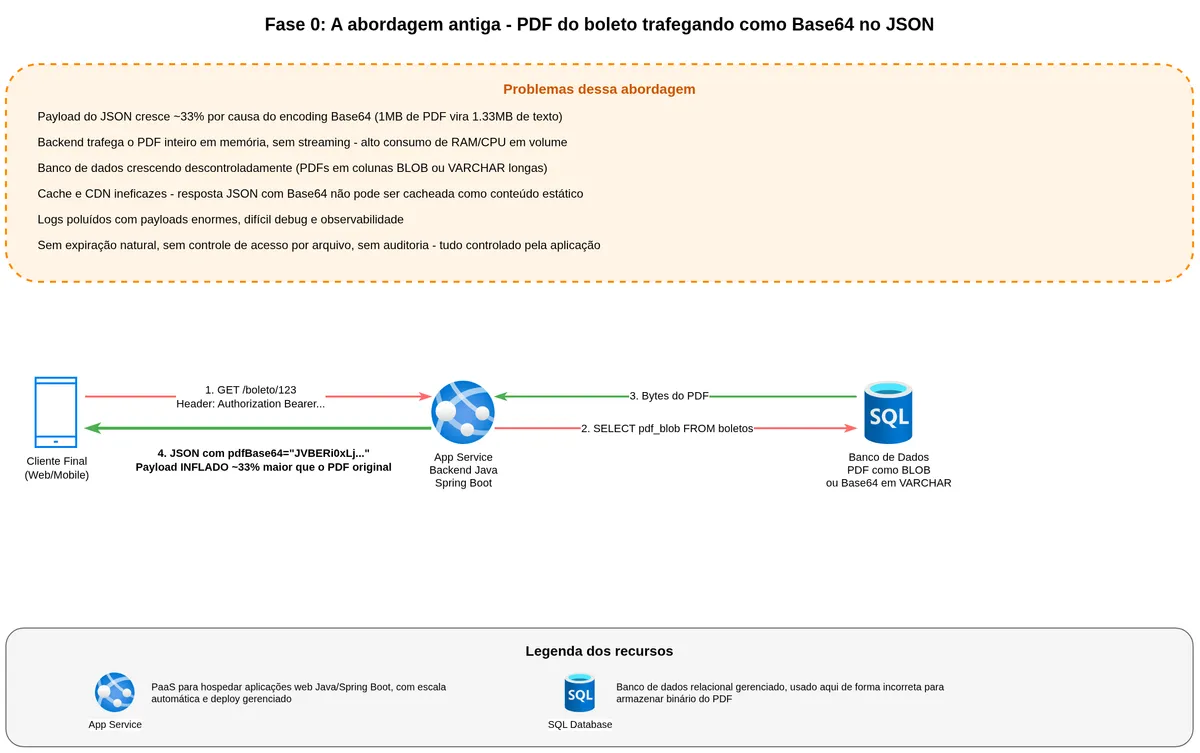
Antes de subir uma única peça de infraestrutura, vale a pena conversar sobre uma decisão que aparece bem cedo nos sistemas que lidam com arquivos, e que é a abordagem que muita gente herda quando entra num projeto e parece prático. Pegando o cenário inicial, o backend gera o PDF do boleto, codifica em Base64, e devolve uma string gigante dentro de um campo do JSON. O cliente decodifica e renderiza ou salva o arquivo. Pronto, integração feita.
Esse padrão é tão comum que vale começar entendendo o que ele oferece de bom, antes de explicar por que vamos abandoná-lo logo de cara.
Por que esse padrão pegou
A primeira razão é histórica e prática. APIs REST trafegam JSON, e JSON não suporta binário puro. Codificar em Base64 é a forma mais imediata de empacotar bytes dentro de um envelope de texto. Isso elimina a necessidade de lidar com multipart/form-data, com upload de arquivo separado, com fluxos de download em duas etapas e tudo cabe num único endpoint, num único contrato.
A segunda razão é de compatibilidade. Praticamente qualquer linguagem ou SDK consegue codificar e decodificar Base64 em uma linha. Frontend pega a string, prefixa com data:application/pdf;base64,... e renderiza direto no browser sem precisar abrir aba nova nem chamar segunda URL. Para soluções rápidas, ou o famoso "quick win", esse atalho é tentador, e é funcional enquanto o volume é baixo.
Onde quebra quando o sistema cresce
Vamos começar pela matemática para trabalhar o primeiro problema. Base64 codifica três bytes binários em quatro caracteres ASCII. O resultado é um payload aproximadamente 33% maior que o arquivo original. Um PDF de 1 MB vira 1,33 MB de texto trafegando na rede. Pense agora numa carteira com cem mil clientes recuperando boleto no início do mês. Esse 33% extra vira gigabytes desnecessários consumindo banda, latência e custo de saída de rede.
O segundo problema é de memória. Para devolver o JSON, o backend precisa carregar o PDF inteiro em memória, fazer o encode, montar a string, e só então responder. Isso quebra qualquer possibilidade de streaming, não tem como mandar o arquivo em pedaços e tudo vira um blob monolítico que o backend segura na heap até a resposta sair. Em volume, isso vira pico de uso de RAM e CPU, garbage collection mais agressivo, e instâncias com escala forçada para o pior caso.
O terceiro problema é de cache e CDN. Conteúdo binário estático é o caso de uso de ouro para CDNs. Você consegue cachear na borda, servir com latência baixíssima, sem nem encostar no backend. Quando o PDF está dentro de um JSON, perdemos isso. O JSON varia por usuário, por boleto, por contexto, e nenhuma camada intermediária consegue cachear o binário separado da metadata.
O quarto problema é operacional. Logs, traces e ferramentas de observabilidade ficam poluídos com payloads imensos. Alguém olha o log de uma requisição e vê uma string de megabytes em hexadecimal. Debugging vira um inferno. Replay de mensagem para teste fica caríssimo. Mascarar para não vazar dado sensível em log também complica e aqui temos tipo de vazamento, gerando fragilidade em LGPD.
O que a abordagem cloud-native propõe
Em arquiteturas modernas, alinhadas com práticas de microservices, serverless e os princípios do 12-factor, vamos separar bem em três partes. Primeiro, o uso do storage de objetos como o Blob Storage para guardar o conteúdo binário. Segundo, a API devolve uma URL para download, idealmente pré-assinada com tempo curto e escopo apenas para aquele arquivo, em vez de devolver os bytes. Terceiro, quando o serviço precisa entregar o arquivo direto, usa streaming HTTP com Content-Type: application/pdf, sem precisar carregar tudo em memória.
Esse modelo entrega quatro ganhos de cara. A rede trafega menos dado, porque cai o overhead de Base64. O backend escala melhor, porque deixa de carregar arquivos inteiros em heap. A CDN volta a fazer sentido, porque a URL aponta para um recurso binário e cacheável. A separação entre metadado (linha digitável, valor, vencimento, status) e conteúdo (o PDF em si) fica explícita no contrato, o que facilita evolução, retenção diferenciada e governança de dados.
E tem outra vantagem que vai aparecer ao longo do texto. Ao tirar o conteúdo binário do banco de dados, a gente para de inflar tabelas com BLOB e VARCHAR enormes, e devolve ao banco o seu papel original, que é guardar dado estruturado consultável. O Storage assume o papel para o qual foi feito, que é guardar bytes em escala.
Conexão com LGPD desde o início
Vale antecipar um ponto específico que vai voltar várias vezes. Quando o boleto trafega como Base64 dentro do JSON, ele se espalha por lugares que ninguém mapeou. Logs de aplicação, headers de retry, mensagens em Kafka ou Service Bus, traces de APM, payload em ferramentas de monitoramento. E em cada um desses lugares vai junto o dado pessoal do pagador (nome, CPF, endereço). Cada cópia desses é um ponto que precisa ser pensado em termos de retenção, controle de acesso e exclusão para atender à LGPD, e na prática nenhum deles foi pensado.
Ao centralizar o boleto num storage de objeto, com URL pré-assinada de curta duração, o dado pessoal fica num único lugar conhecido, com controle de acesso, auditoria, retenção e exclusão definidos. A cloud-native resolve o problema técnico e dá a base material para falar de conformidade com a lei sem depender de processo manual construído depois.
Com esse alinhamento feito, vamos entrar no contexto do boleto e começar a desenhar a versão zero do backend.
O que estamos protegendo antes de qualquer linha de código
Antes de qualquer infraestrutura, vamos alinhar o que é o objeto central desse sistema. O boleto bancário no Brasil é um documento financeiro com prazo, valor e código de barras. Ele costuma viver semanas ou meses antes do vencimento, vira histórico depois de pago, e em muitos cenários precisa ser guardado por anos por obrigação fiscal e regulatória, especialmente em produtos financeiros.
Ou seja, estamos falando de um arquivo que tem valor monetário direto se for adulterado, que carrega dado pessoal porque traz nome, CPF e CNPJ do pagador, e que normalmente tem exigência de retenção por parte dos órgãos reguladores. Tudo isso vai pesar em cada escolha que faremos mais à frente. Quando eu falar de imutabilidade, ciclo de vida e auditoria, lembre desse contexto, porque é ele que dá o peso para cada decisão.
Pelo lado da LGPD, o boleto se enquadra como dado pessoal pelo simples fato de carregar CPF, nome e endereço do pagador. Isso significa que cada operação sobre ele, geração, armazenamento, compartilhamento, retenção e eliminação, está sujeita aos princípios do art. 6 da lei. Os principais que vão aparecer ao longo do texto são finalidade, adequação, necessidade, segurança, prevenção e prestação de contas. Cada camada que adicionarmos precisa contribuir para um desses, ou então é peso morto que não justifica o custo.
"O armazenamento imutável ajuda organizações de saúde, instituições financeiras e setores relacionados, em particular corretoras, a guardar dados com segurança. O armazenamento imutável pode ser usado em qualquer cenário para proteger dados críticos contra modificação ou exclusão." (Microsoft Learn, Overview of immutable storage for blob data, tradução livre)
Esse trecho da própria documentação da Microsoft mostra que o caminho que vamos trilhar tem nome e tem caso de uso conhecido. Vamos começar do zero e ir subindo a régua.
Entendendo onde os arquivos vão morar: Storage Account, Container e Blob
Antes de escrever código, precisamos entender com o que estamos trabalhando. O Azure Blob Storage tem três conceitos que se encaixam em hierarquia, e confundir qualquer um deles vai gerar problemas de design desde cedo.
O primeiro conceito é a Storage Account, que é a conta de armazenamento. Pensa nela como um endereço postal exclusivo na nuvem. Ela é um namespace global que recebe um nome único no mundo inteiro, e é por isso que a URL do seu storage termina com seunome.blob.core.windows.net, esse nome é seu e de mais ninguém. Ela também é a unidade de cobrança e a unidade de configuração de segurança. Quando você configura firewall, replicação geográfica, criptografia ou controle de acesso, você faz isso na Storage Account. Pense nela como o portão de entrada do condomínio.
O segundo conceito é o Container, que mora dentro da Storage Account. Ele é um agrupamento lógico de arquivos, similar a uma pasta, mas sem hierarquia real de subpastas (qualquer "hierarquia" é apenas convenção de nome usando barras). Você pode ter containers separados para boletos de clientes pessoas físicas, para boletos de pessoas jurídicas, para boletos de um determinado produto. O container também tem configuração de acesso própria, onde você pode dizer se os arquivos dentro dele são públicos, privados ou acessíveis por política. Pense nele como um apartamento dentro do condomínio.
O terceiro conceito é o Blob, que é o arquivo em si. O nome vem do inglês Binary Large Object, objeto binário grande, e é literalmente qualquer sequência de bytes. Um PDF de boleto, uma imagem, um log, um vídeo. Cada blob tem um nome dentro do container, e esse nome forma a chave de acesso. Dentro da Storage Account, o endereço completo de qualquer blob é sempre no formato https://conta.blob.core.windows.net/container/nome-do-blob.
flowchart TB
SA[Storage Account
nome único global] --> CA[Container: boletos-pf]
SA --> CB[Container: boletos-pj]
SA --> CC[Container: contratos]
CA --> B1[Blob: boleto-abc123.pdf]
CA --> B2[Blob: boleto-def456.pdf]
CB --> B3[Blob: boleto-cnpj-001.pdf]Por que essa separação importa para segurança? Porque cada container pode ter política de acesso independente. Você pode deixar o container de logos da empresa como público (quem precisar da imagem pode acessar sem autenticação), enquanto o container de boletos é estritamente privado. E pode ter ainda um container de contratos com política de retenção forçada. A granularidade do container é o mínimo que você deve pensar quando for organizar seus dados.
Versão zero, o código que funciona mas que dá medo
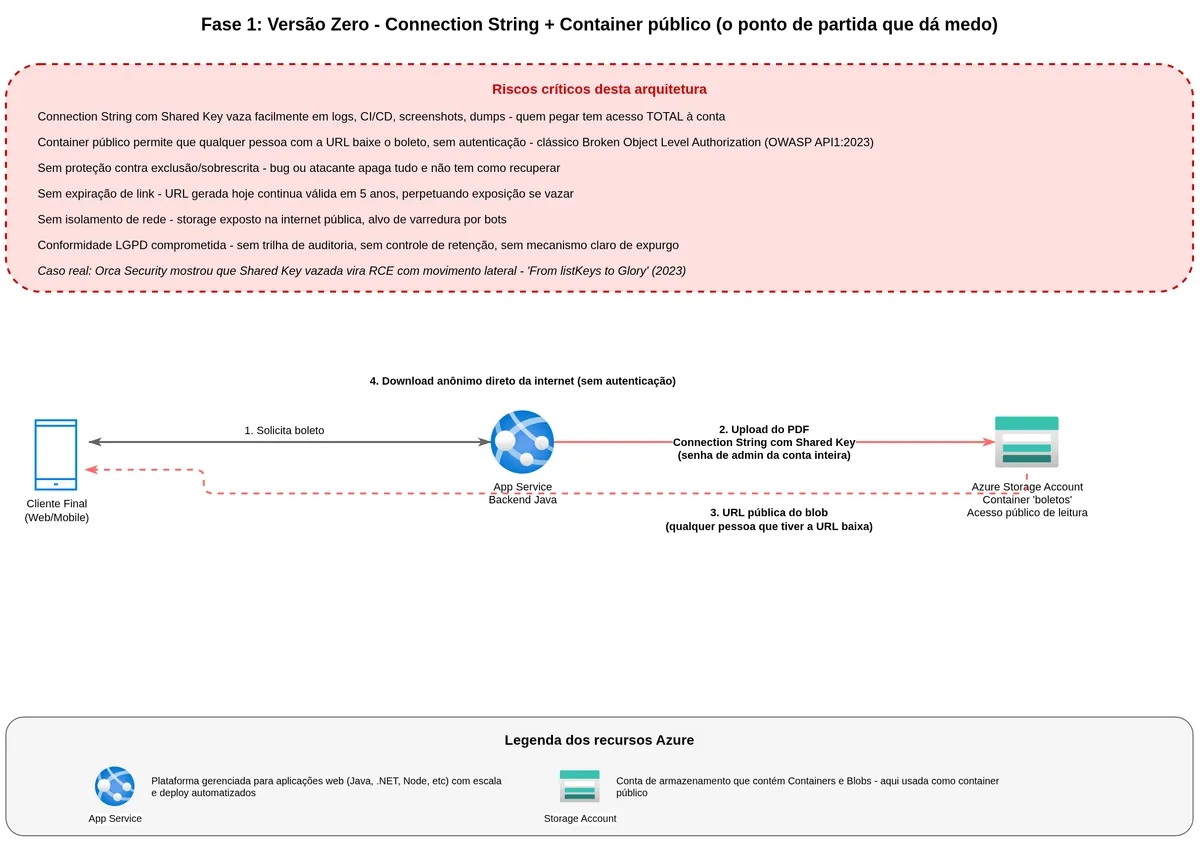
Agora sim, o ponto de partida. Um serviço Spring Boot recebe uma requisição HTTP do cliente, gera o PDF do boleto, sobe pro Azure Blob Storage usando uma chave de conta lida de uma variável de ambiente, e devolve uma URL pública do blob. O código abaixo é o anti-padrão: funciona, mas expõe credenciais de administrador da conta inteira. Todo o restante do artigo vai explicar por que isso é perigoso e como substituir cada parte.
@Service
public class BoletoStorageService {
private final BlobServiceClient blobServiceClient;
private final String containerName = "boletos";
public BoletoStorageService(@Value("${azure.storage.connection-string}") String conn) {
this.blobServiceClient = new BlobServiceClientBuilder()
.connectionString(conn)
.buildClient();
}
public String upload(String fileName, byte[] pdf) {
BlobContainerClient container = blobServiceClient.getBlobContainerClient(containerName);
BlobClient blob = container.getBlobClient(fileName);
blob.upload(BinaryData.fromBytes(pdf), true);
return blob.getBlobUrl();
}
}A connection string que entra ali tem um formato parecido com DefaultEndpointsProtocol=https;AccountName=meuaccount;AccountKey=AbCdEfGh...;EndpointSuffix=core.windows.net. Ela traz dentro de si o nome da conta, o endpoint, e a famosa Shared Key, que é a chave de acesso à conta.
Tudo funciona. O time celebra. O cliente baixa o boleto. O QA aprova. E aí é a hora em que o arquiteto experiente fica desconfortável.
flowchart LR
A[Cliente Web/Mobile] -->|HTTPS| B[Backend Java
Spring Boot]
B -->|Connection String
com Shared Key| C[(Azure Blob Storage
Container 'boletos')]
B -->|URL pública do Blob| A
C -.->|Acesso anônimo
se container público| AO que é a Shared Key e por que ela é perigosa
Antes de listar os problemas, vale entender o que a Shared Key de fato é, porque o nome soa técnico mas a analogia é simples.
Quando você cria uma Storage Account, o Azure gera automaticamente duas chaves de 512 bits, chamadas de chave primária e chave secundária. Essas chaves funcionam como senhas de administrador da conta. Qualquer sistema ou pessoa que apresentar uma dessas chaves para o Azure consegue fazer absolutamente tudo na conta: ler, escrever, apagar, listar, reconfigurar, e até gerar outros tokens de acesso em nome da conta. Não existe hierarquia de permissão com a Shared Key. Ou você tem, e pode tudo, ou você não tem, e não pode nada.
"As chaves de acesso da conta de armazenamento concedem acesso completo aos dados da conta e a possibilidade de gerar tokens SAS." (Microsoft Learn, Manage account access keys, tradução livre)
É exatamente como a chave do cofre-forte de um banco. Quem pegar essa chave não precisa de mais nada. Pode entrar, sair, pegar o conteúdo, colocar conteúdo diferente, mudar a combinação do cofre, e ainda fazer cópias para outras pessoas. E o pior, o banco não sabe diferenciar se foi você que abriu o cofre ou se foi outra pessoa, porque a chave é a mesma.
O problema prático é que a connection string, que carrega essa chave, acaba indo para variáveis de ambiente, para arquivos de configuração, para CI/CD pipelines, para logs de startup da aplicação, para screenshots de debugging no Slack. Uma vez que vaza, o raio de destruição é total.
A Orca Security documentou em 2023 um caminho de ataque que começa exatamente com a obtenção de uma Shared Key de uma Storage Account. A partir daí, um atacante consegue escalar privilégios dentro do ambiente Azure, comprometer Azure Functions associadas ao storage, e eventualmente executar código remoto em outras partes da infraestrutura.
"Com essa chave, obtida por vazamento ou por uma role apropriada do AD, um atacante não apenas consegue acesso completo às contas de storage e a ativos potencialmente críticos do negócio, como também pode se mover lateralmente no ambiente e até executar código remoto." (Orca Security, From listKeys to Glory, tradução livre)
O problema da URL pública
Além da chave, tem um segundo problema. Se o container está configurado como público para leitura, a URL que o backend retorna é acessível por qualquer pessoa que a conheça. Não precisa de senha, não precisa de autenticação, não precisa de nada. Basta ter a URL.
Pior, se o nome do arquivo for previsível, como boleto_12345.pdf, um atacante pode varrer o universo de IDs e baixar boletos de outros clientes. Isso é exatamente o que a OWASP chama de Broken Object Level Authorization (BOLA), o primeiro item da lista de ameaças em APIs.
"Todo endpoint de API que recebe um identificador de objeto, e executa qualquer ação sobre esse objeto, deve implementar verificação de autorização em nível de objeto. A verificação precisa validar que o usuário autenticado tem permissão para executar a ação solicitada sobre o objeto solicitado." (OWASP API Security, API1:2023 Broken Object Level Authorization, tradução livre)
Usar um GUID aleatório no nome do arquivo atenua, mas não resolve, porque a URL ainda funciona para qualquer um que a capturar, seja via log, via histórico de browser, via e-mail encaminhado.
Pelo lado da LGPD, essa versão zero falha em pelo menos três princípios. Falha em segurança (art. 6, VII), porque não tem controle de acesso efetivo. Falha em prevenção (art. 6, VIII), porque não tem mecanismo para impedir que outra pessoa baixe um boleto que não é seu. E falha em prestação de contas (art. 6, X), porque não há trilha de quem acessou o quê. Se um vazamento acontece nesse desenho, a empresa não consegue nem saber a extensão para reportar à ANPD no prazo legal.
Vamos resolver esses dois problemas em camadas.
Primeira camada: entendendo identidade antes de mudar o código
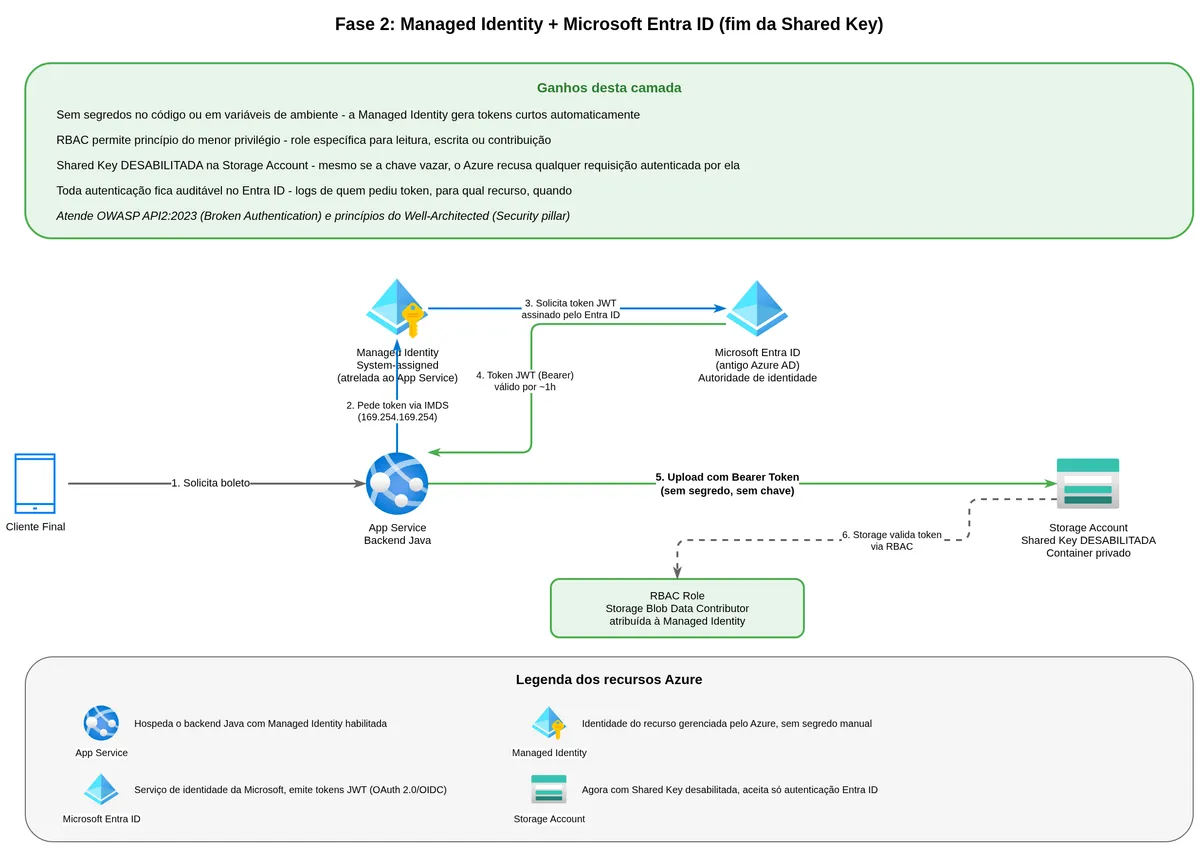
Para resolver o problema da Shared Key, vou apresentar uma abordagem diferente de autenticação. Mas antes de mudar o código, preciso te explicar três conceitos que se encadeiam, porque sem entender cada um separado, o conjunto parece magia.
O que é o Microsoft Entra ID
O Microsoft Entra ID, que antes se chamava Azure Active Directory, é o serviço de identidade da Microsoft para a nuvem. Mas o que isso significa na prática?
Pensa em identidade como um problema de confiança. Quando você entra num prédio corporativo e mostra seu crachá para o porteiro, o porteiro não sabe quem você é pessoalmente, ele confia no crachá porque o departamento de RH emitiu aquele crachá. O RH é a autoridade que diz "essa pessoa é quem ela diz que é". Se o crachá for falso, o problema é que alguém forjou a credencial, mas o mecanismo de confiança é legítimo.
O Entra ID desempenha exatamente esse papel de autoridade de identidade, só que para sistemas de software. Ele é o "cartório digital" que diz "esse sistema ou essa pessoa é quem diz ser". Toda vez que um serviço precisa provar para outro que tem permissão para fazer algo, ele busca no Entra ID um documento de identidade chamado token. Esse token é assinado digitalmente pelo Entra ID, e qualquer serviço que confie no Entra ID consegue verificar que aquele token é legítimo sem precisar checar na origem.
Tecnicamente, o Entra ID implementa os protocolos OAuth 2.0 e OpenID Connect, que são padrões abertos de delegação de autorização e autenticação. O Azure Storage, o Azure Key Vault, o Azure SQL, entre outros, todos confiam no Entra ID como autoridade. Isso significa que você pode usar o mesmo mecanismo de identidade para autorizar acesso a todos eles.
O que é uma Managed Identity e por que ela existe
Agora que você entende o Entra ID como autoridade de identidade, surge uma questão. Se os serviços do Azure precisam de um documento de identidade (token) para falar entre si, como eles pegam esse documento sem guardar uma senha em algum lugar?
A resposta é a Managed Identity, a identidade gerenciada. É uma identidade atrelada diretamente ao recurso computacional, como um App Service, um Container App ou uma Azure Function, e gerenciada completamente pelo Azure. Não existe senha, não existe chave, não existe segredo que o desenvolvedor precise guardar ou rotacionar.
Como funciona internamente? O Azure cria e mantém um certificado vinculado ao recurso. Quando a aplicação dentro desse recurso precisa de um token de acesso, ela faz uma chamada HTTP para um endpoint especial disponível apenas dentro da infraestrutura do Azure, chamado de IMDS (Instance Metadata Service). Esse endpoint responde com um token JWT assinado pelo Entra ID, afirmando que aquele recurso específico está autenticado. A renovação desse token acontece automaticamente antes de expirar.
O desenvolvedor não precisa saber o certificado, não precisa guardar segredo, não precisa configurar rotação. Basta dizer "meu App Service tem uma Managed Identity chamada X", e dar para essa identity as permissões certas nos recursos que ela precisa acessar.
"Uma identidade gerenciada permite que sua aplicação se conecte de forma segura a outros recursos do Azure sem o uso de chaves secretas ou outros segredos da aplicação." (Microsoft Learn, Authenticate Azure-hosted Java apps by using a system-assigned managed identity, tradução livre)
Existem dois sabores de Managed Identity. A System-Assigned é criada automaticamente quando você habilita a feature no recurso, tem o mesmo ciclo de vida do recurso (quando você deleta o App Service, a identity some junto), e é bom para quando cada recurso precisa da sua identidade própria. A User-Assigned é criada separadamente como um recurso independente e pode ser atribuída a múltiplos recursos, sendo útil quando vários serviços precisam das mesmas permissões.
O que é o DefaultAzureCredential
Agora que você entende o Entra ID e as Managed Identities, fica fácil entender o DefaultAzureCredential. Ele é uma classe do SDK Java da Azure que implementa uma cadeia de tentativas de autenticação. Em produção, tenta pegar token via Managed Identity. Em desenvolvimento local, tenta via Azure CLI, via IntelliJ, via Visual Studio Code, na ordem. Quem conseguir primeiro, ganha.
Isso resolve um problema prático enorme: você escreve o mesmo código para local e para produção, sem variável especial nem ifdef. Em local o dev usa suas credenciais pessoais via az login. Em produção, a Managed Identity entra automaticamente.
"O DefaultAzureCredential suporta múltiplos métodos de autenticação e determina qual método deve ser usado em tempo de execução. Essa abordagem permite que sua aplicação use métodos de autenticação diferentes em ambientes diferentes (local versus produção) sem implementar código específico para cada ambiente." (Microsoft Learn, Quickstart: Azure Blob Storage library - Java, tradução livre)
A mudança no código
Com esses três conceitos entendidos, a mudança no código fica simples:
@Service
public class BoletoStorageService {
private final BlobServiceClient blobServiceClient;
private final String containerName = "boletos";
public BoletoStorageService(@Value("${azure.storage.endpoint}") String endpoint) {
DefaultAzureCredential credential = new DefaultAzureCredentialBuilder().build();
this.blobServiceClient = new BlobServiceClientBuilder()
.endpoint(endpoint)
.credential(credential)
.buildClient();
}
public void upload(String fileName, byte[] pdf) {
BlobContainerClient container = blobServiceClient.getBlobContainerClient(containerName);
BlobClient blob = container.getBlobClient(fileName);
blob.upload(BinaryData.fromBytes(pdf), true);
}
}A chave sumiu. Só o endpoint permanece, que é o nome público do storage account, sem segredo nenhum embutido. O DefaultAzureCredential cuida do resto.
Para que isso funcione, você precisa atribuir uma role do Azure RBAC para a Managed Identity do seu serviço. Role-Based Access Control é o sistema de permissões do Azure que diz "a identity X pode fazer as ações Y no recurso Z". Para subir e ler arquivos, a role Storage Blob Data Contributor é suficiente. Para apenas ler, Storage Blob Data Reader já basta.
Se você quiser granularidade maior, pode ter duas Managed Identities diferentes: uma com Storage Blob Data Contributor no serviço que gera boletos, e outra com Storage Blob Data Reader no serviço que entrega boletos. Se uma das partes for comprometida, o atacante tem acesso limitado àquela função específica.
flowchart LR
APP[App Service
com System-Assigned Identity] -->|1. Requisição de token via IMDS| IMDS[169.254.169.254
Instance Metadata Service]
IMDS -->|2. Token JWT assinado| APP
APP -->|3. Requisição com Bearer Token| SA[(Storage Account)]
SA -->|4. Verifica token com Entra ID| EN[Microsoft Entra ID]
EN -->|5. Token válido, permissão OK| SA
SA -->|6. Responde à operação| APPVocê ganha segurança enorme porque não existe mais segredo para vazar. Ganha operação mais simples porque não tem rotação de chave para fazer nem alerta de chave expirando. Perde em portabilidade imediata porque para rodar localmente o dev precisa fazer az login e ter permissão atribuída também. Perde em simplicidade de debugging inicial porque problemas de autenticação viram "token inválido" sem mensagem muito descritiva na primeira vez.
Segunda camada: SAS token, o tíquete de acesso temporário
Resolvemos o problema do backend se autenticar no storage sem guardar segredo. Mas ainda temos o problema de como entregar o boleto para o cliente final de forma segura. Se o backend baixa o PDF e devolve no corpo da resposta HTTP, ele fica no caminho crítico de toda transferência de dados, pagando latência e custo de banda. Se ele devolve a URL direta do blob sem proteção, qualquer um que interceptar ou receber a URL pode baixar.
A solução é o SAS token, Shared Access Signature. Vou explicar o que ele é de verdade antes de mostrar código.
O que é um SAS e o que ele representa
Um SAS é uma assinatura criptográfica que você anexa à URL de um recurso Azure Storage. Quando o Azure Storage recebe uma requisição com essa assinatura, ele consegue verificar que alguém com autoridade legítima emitiu aquele tíquete, e que as condições daquele tíquete ainda estão válidas.
Pensa no SAS como um ingresso de show. O ingresso diz: "quem apresentar isso pode entrar pela porta 3 no dia 15 de abril até as 22h, tem direito a um assento na área VIP". Quem emitiu o ingresso assinou embaixo. A portaria não precisa ligar pro organizador do show para confirmar, ela verifica a assinatura e lê as condições. Se o ingresso expirou, entra não. Se é para a porta 4 e a pessoa foi para a porta 3, entra não. O ingresso carrega tudo que é necessário para a decisão.
A URL de um blob com SAS tem um formato parecido com este:
https://meuaccount.blob.core.windows.net/boletos/boleto-abc123.pdf
?sp=r
&st=2026-04-25T14:00:00Z
&se=2026-04-25T14:15:00Z
&spr=https
&sv=2021-06-08
&sr=b
&sig=AbCdEfGh...Cada parâmetro tem um papel. sp=r significa permissão de leitura apenas. st e se são os instantes de início e expiração. spr=https força o protocolo seguro. sr=b especifica que o escopo é um blob específico (não o container inteiro). E sig é a assinatura criptográfica que amarra todos esses parâmetros juntos. Se alguém tentar alterar qualquer um dos parâmetros, a assinatura falha e o Azure Storage rejeita.
Os três tipos de SAS e o que cada um significa
Existem três sabores de SAS, e a diferença entre eles é quem assina e o que pode ser assinado. Entender isso é importante porque a escolha errada aqui foi o que custou caro para a Microsoft no incidente dos 38TB.
O primeiro é o Account SAS. Ele é assinado com a Shared Key da conta de armazenamento e pode cobrir qualquer serviço dentro da conta (Blob, Queue, Table, Files) com qualquer combinação de permissões. É o mais poderoso e o mais perigoso. Imagine que você assinou um ingresso com a chave mestra do evento, e esse ingresso dá acesso a tudo. É exatamente o que foi usado no incidente da Microsoft, com validade configurada para 2051, ou seja, praticamente eterna.
O segundo é o Service SAS. Ele é assinado com a Shared Key da conta, mas é limitado a um serviço específico (apenas Blob, por exemplo). Ainda usa a chave mestra para assinar, então se você precisar invalidar, precisa rotacionar a chave da conta inteira.
O terceiro é o User Delegation SAS, e este é o que a Microsoft recomenda.
"Para cenários em que assinaturas de acesso compartilhado são usadas, a Microsoft recomenda usar uma user delegation SAS. Uma user delegation SAS é assegurada com credenciais do Microsoft Entra em vez da chave da conta, o que oferece segurança superior." (Microsoft Learn, Grant limited access to data with shared access signatures, tradução livre)
O que é o User Delegation SAS e por que ele é diferente
O User Delegation SAS é assinado não com a Shared Key da conta de armazenamento, mas com uma User Delegation Key, que é uma chave temporária emitida pelo próprio Azure Storage em resposta a uma requisição autenticada via Entra ID.
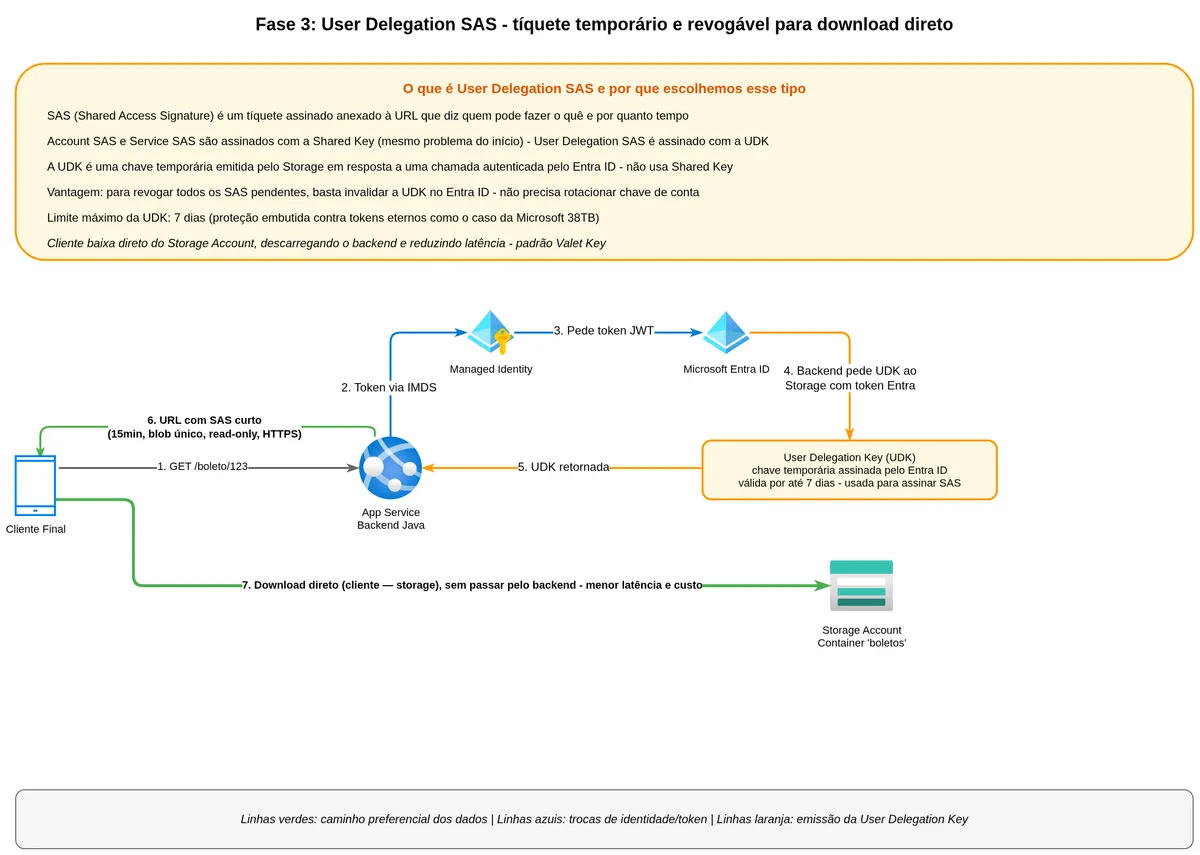
Vamos decompor isso passo a passo, porque o mecanismo é elegante.
Primeiro, o backend (autenticado via Managed Identity no Entra ID) faz uma chamada ao Azure Storage pedindo uma User Delegation Key. Essa chamada é autenticada com o token JWT da Managed Identity. O Azure Storage verifica se essa identity tem permissão para gerar a chave, e se tiver, devolve uma chave temporária. Essa chave é válida por no máximo sete dias, e nada mais.
Segundo, o backend usa essa User Delegation Key para assinar os parâmetros do SAS token que quer emitir: blob específico, permissão de leitura, expiração em quinze minutos, protocolo HTTPS obrigatório.
Terceiro, o backend devolve essa URL com SAS para o cliente final. O cliente faz download direto do blob usando a URL, sem passar pelo backend.
Quarto, quando queira revogar todos os SAS pendentes, o backend não precisa rotacionar a chave da conta de armazenamento (que quebraria tudo). Basta revogar a User Delegation Key no Entra ID, e instantaneamente todos os SAS assinados por aquela chave param de funcionar.
sequenceDiagram
participant CLI as Cliente Final
participant APP as Backend Java
participant ENTRA as Microsoft Entra ID
participant SA as Azure Storage
APP->>ENTRA: Obter token para Storage (via Managed Identity)
ENTRA-->>APP: Token JWT da Managed Identity
APP->>SA: POST getUserDelegationKey (com token JWT)
SA->>ENTRA: Validar token
ENTRA-->>SA: Token válido
SA-->>APP: User Delegation Key (válida por até 7 dias)
CLI->>APP: GET /boleto/{id} (autenticado na API)
APP->>APP: Gera User Delegation SAS (blob único, read, 15min)
APP-->>CLI: URL com SAS assinado pela UDK
CLI->>SA: GET boleto.pdf?[SAS params]
SA->>SA: Verifica assinatura com UDK
SA-->>CLI: PDF do boleto (direto, sem passar pelo backend)A vantagem de revogabilidade é enorme. Imagine que você descobriu que um conjunto de SAS foi gerado com permissões erradas ou para o usuário errado. Com Service SAS, sua única opção é rotacionar a chave da conta, o que quebra absolutamente tudo que depende daquela chave. Com User Delegation SAS, você revoga a UDK específica e apenas aquele conjunto de SAS para de funcionar.
Outro ponto importante é que a User Delegation Key tem validade máxima de sete dias.
"User delegation key. O valor do tempo de expiração é, no máximo, sete dias a contar da criação do token SAS. O SAS deixa de ser válido depois que a user delegation key expira, então um SAS com tempo de expiração maior que sete dias ainda assim só será válido por sete dias." (Microsoft Learn, Shared access signature tokens, tradução livre)
Isso é uma proteção embutida. Você não consegue criar um User Delegation SAS eterno, porque a chave que o assina expira em no máximo sete dias.
O que aconteceu na Microsoft com o SAS mal configurado
Em junho de 2023, pesquisadores da Wiz Research descobriram um repositório no GitHub da equipe de pesquisa de IA da Microsoft que continha uma URL com um SAS token embutido. O token estava configurado como Account SAS (o tipo mais permissivo), com permissões de "full control" (não só leitura, mas escrita e exclusão também), e com validade configurada para 2051, ou seja, trinta anos no futuro.
"O simples ato de compartilhar um conjunto de dados de IA levou a um vazamento de dados grave, contendo mais de 38 TB de dados privados. A causa raiz foi o uso de tokens Account SAS como mecanismo de compartilhamento. Pela falta de monitoramento e governança, tokens SAS representam um risco de segurança e seu uso deveria ser o mais limitado possível." (Wiz Research, 38TB of data accidentally exposed by Microsoft AI researchers, tradução livre)
A URL não estava apontando para o container de modelos de IA que o time queria compartilhar. Estava apontando para a conta inteira, que continha 38 terabytes de dados, incluindo backups de máquinas de funcionários, chaves privadas, senhas e mais de 30 mil mensagens internas do Microsoft Teams.
O que tornou o problema pior foi que o SAS tinha permissão de escrita e exclusão. Qualquer pessoa que encontrasse aquela URL poderia não só ler os dados, como apagá-los ou substituí-los por conteúdo malicioso. E durante três anos (de julho de 2020 até junho de 2023) esse link ficou vivo em código aberto público no GitHub.
Três anos de exposição com permissão de escrita e exclusão em dados corporativos. O incidente documenta quatro controles que faltaram: escopo mínimo, validade curta, User Delegation em vez de Account SAS, e monitoramento ativo de SAS gerados.
O código com User Delegation SAS
public String generateDownloadUrl(String blobName) {
BlobContainerClient container = blobServiceClient
.getBlobContainerClient(containerName);
BlobClient blob = container.getBlobClient(blobName);
OffsetDateTime now = OffsetDateTime.now(ZoneOffset.UTC);
// Pede a User Delegation Key ao Azure Storage
// autenticando com a Managed Identity do serviço
UserDelegationKey udk = blobServiceClient
.getUserDelegationKey(now, now.plusHours(1));
// Define as permissões e condições do SAS
BlobSasPermission perms = new BlobSasPermission()
.setReadPermission(true);
BlobServiceSasSignatureValues values =
new BlobServiceSasSignatureValues(now.plusMinutes(15), perms)
.setProtocol(SasProtocol.HTTPS_ONLY)
.setStartTime(now);
// Assina o SAS com a User Delegation Key
String sas = blob.generateUserDelegationSas(values, udk);
return blob.getBlobUrl() + "?" + sas;
}Repare nos parâmetros. Quinze minutos de validade significa que se o cliente não baixar dentro desse tempo, o link expira e ele precisa pedir um novo. O link foi feito para ser descartável. Blob único significa que o SAS dá acesso apenas ao boleto-abc123.pdf, e nada mais do mesmo container. Leitura apenas significa que o portador não pode escrever, apagar, ou renomear. HTTPS obrigatório significa que se alguém tentar usar o link via HTTP, o Azure rejeita.
"Use SAS de curta duração. Sempre defina um tempo de expiração próximo no momento de criar um SAS, e faça com que os clientes solicitem novas URLs SAS quando necessário. O Azure Storage recomenda uma hora ou menos para todas as URLs SAS." (Microsoft Security Response Center, tradução livre)
E tem uma configuração importante que vale fazer na Storage Account inteira: desabilitar a autorização via Shared Key completamente.
"Para impedir que usuários acessem dados na sua conta de armazenamento usando Shared Key, você pode desabilitar a autorização por Shared Key na conta de armazenamento." (Microsoft Learn, Manage account access keys, tradução livre)
Com isso, nem mesmo quem tiver a chave de conta consegue usá-la. O Azure simplesmente recusa qualquer requisição autenticada por Shared Key. Você força todo o acesso a passar pelo Entra ID, seja Managed Identity, seja User Delegation Key.
Terceira camada: o problema de encontrar o boleto certo e a separação de responsabilidades
Até aqui, resolvemos como autenticar o serviço e como entregar o boleto de forma segura. Ainda não está resolvido como identificar qual blob corresponde ao boleto de um cliente específico.
A resposta ingênua é listar todos os blobs do container e filtrar pelo nome. Isso é um erro que parece pequeno no início e vira caro logo depois.
Por que listar blobs é um problema
O Blob Storage é um armazenamento de objetos, do inglês object storage. Ele é um repositório de chave-valor gigante onde a chave é o nome do blob e o valor são os bytes. Não existe índice secundário nativo, não existe busca por atributo, não existe query. Para encontrar todos os boletos do CPF 123.456.789-00, você precisaria listar todos os blobs do container e filtrar na memória da aplicação, o que pode significar milhões de registros trafegando.
Além do custo computacional, existe o custo financeiro. O Azure cobra por operação de API no Storage. Cada página de listagem é uma operação. Para um container com dez milhões de blobs, listar tudo seria caríssimo e extremamente lento.
"Todas as requisições feitas à conta de storage, incluindo as requisições feitas pela execução das políticas, contam para o mesmo limite de requisições por segundo." (Microsoft Learn, Azure Blob Storage lifecycle management overview, tradução livre)
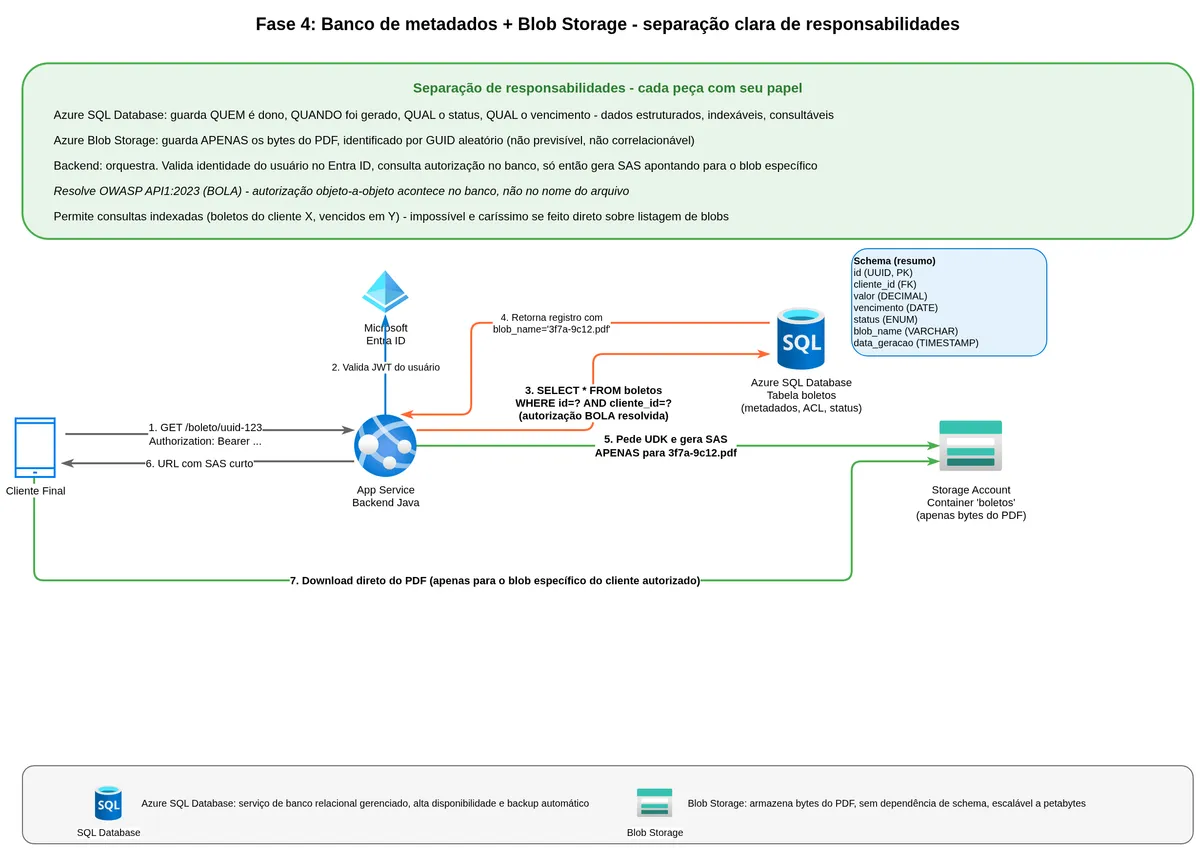
A solução arquitetural correta é separar responsabilidades com clareza: o banco de dados relacional é quem sabe quem é dono de qual boleto, quando vence, qual o status, qual o produto. O Blob Storage é quem guarda os bytes do PDF. Eles se integram por uma referência estável.
Separando metadata de conteúdo
A modelagem fica assim. No banco de dados você tem uma tabela de boletos com colunas como id (GUID), cliente_id, vencimento, valor, status, data_geracao, blob_name. O campo blob_name aponta para o blob correspondente no storage, e esse blob_name é um GUID gerado na hora da criação, não um número sequencial previsível.
Usar GUID aleatório como nome do blob é também uma forma de pseudonimização nos termos do art. 13, parágrafo 4 da LGPD. Mesmo que a URL do blob vaze num log ou trace de APM, o GUID não revela a quem aquele documento pertence. Para associar um blob ao seu titular, é necessário cruzar com a tabela de metadados no banco, que está protegida por autenticação separada. Essa separação não elimina o dado pessoal, mas reduz o risco de exposição indireta por vazamento de URL.
flowchart TB
subgraph Banco de Dados Relacional
TB[Tabela boletos
id: uuid
cliente_id: fk
vencimento: date
valor: decimal
status: enum
blob_name: varchar]
end
subgraph Azure Blob Storage
BL[(Container: boletos
3f7a9c12.pdf
9d1b2e45.pdf
7c4f8a33.pdf)]
end
TB -->|blob_name = '3f7a9c12.pdf'| BLQuando um cliente pede o boleto, o fluxo passa primeiro pelo banco: "esse cliente_id tem permissão de ver o boleto com esse id?" Se a resposta for não, a requisição é rejeitada antes de qualquer interação com o blob. Se for sim, o backend pega o blob_name daquele registro e gera o SAS apontando para aquele blob específico.
Esse padrão resolve o BOLA (Broken Object Level Authorization) pela raiz. A autorização acontece na camada de domínio, com toda a lógica de negócio disponível, antes de qualquer acesso ao storage. Não dá para adivinhar o nome do blob porque é um GUID. E mesmo que alguém descubra o GUID, um SAS expirado não funciona.
flowchart LR
CLI[Cliente] -->|GET /boleto/id-123| APP[Backend Java]
APP -->|SELECT * FROM boletos
WHERE id = 'id-123'
AND cliente_id = 'cliente-X'| DB[(Banco SQL)]
DB -->|blob_name = '3f7a9c12.pdf'| APP
APP -->|Gera User Delegation SAS
para 3f7a9c12.pdf| SA[(Azure Storage)]
APP -->|URL com SAS| CLI
CLI -->|Download direto| SAA separação também abre espaço para relatórios, busca por período, filtro por status de pagamento, histórico de acessos e tudo que o negócio vai pedir um dia. O Blob Storage não foi feito para esse tipo de consulta, mas o banco de dados foi.
Quarta camada: isolando a rede com Private Endpoints
Mesmo com autenticação baseada em identidade e SAS bem calibrado, a Storage Account ainda tem um endpoint público acessível da internet. O endereço meuaccount.blob.core.windows.net responde para qualquer requisição que chegar, mesmo que acabe rejeitando por falta de autenticação. Isso é vetor de reconhecimento (descobrir que a conta existe), de ataques de negação de serviço contra o endpoint público, e de exfiltração de dados caso uma identidade seja comprometida.
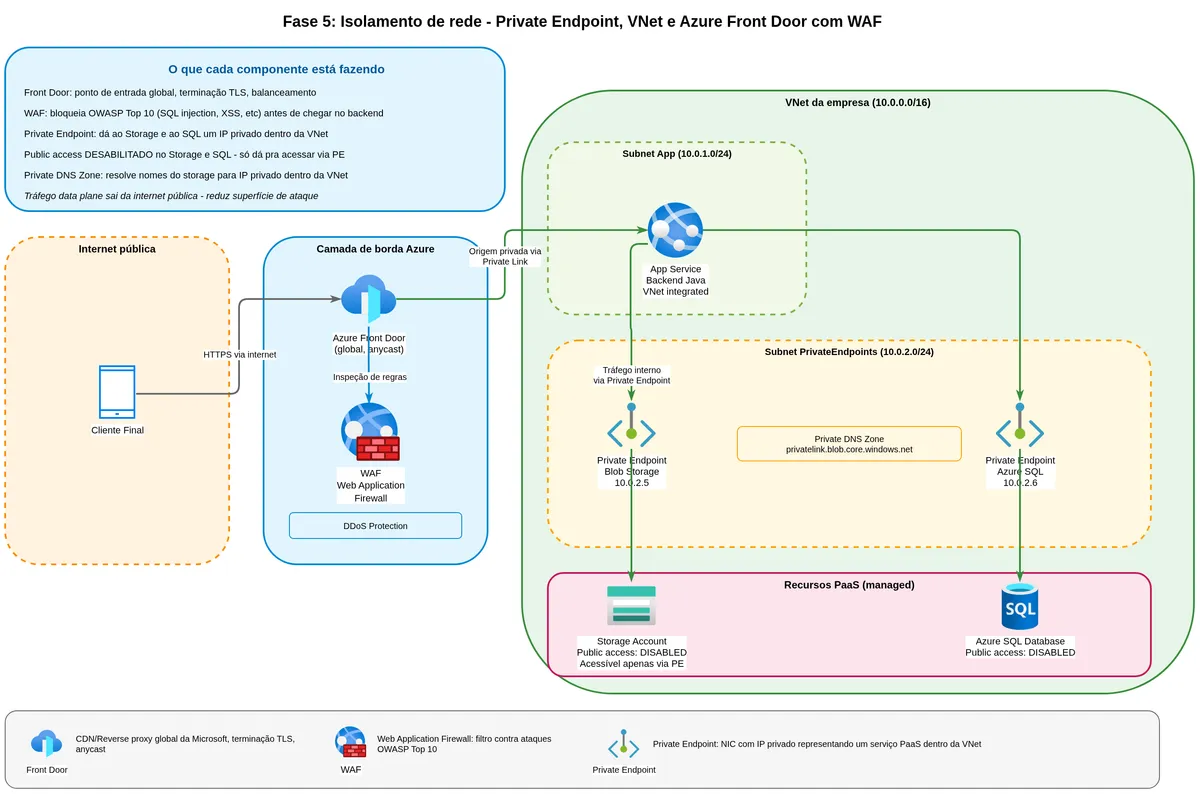
O que é um Private Endpoint e o que ele muda
Um Private Endpoint é uma interface de rede virtual dentro da sua VNet que representa um serviço PaaS (como o Blob Storage) com um endereço IP privado. Em vez da comunicação sair pela internet e entrar pelo endpoint público do Azure, ela fica dentro da rede privada, viajando pelo backbone da Microsoft.
"Você pode usar private endpoints para suas contas de Azure Storage, permitindo que clientes em uma Virtual Network acessem dados de forma segura via Private Link. O private endpoint usa um endereço IP separado, do espaço de endereçamento da virtual network, para cada serviço da conta de storage. O tráfego de rede entre os clientes na virtual network e a conta de storage trafega pela própria virtual network e por um private link na rede backbone da Microsoft, eliminando a exposição à internet pública." (Microsoft Learn, Use private endpoints for Azure Storage, tradução livre)
E depois de criar o Private Endpoint, você configura o firewall do Storage Account para negar qualquer acesso pelo endpoint público. A partir daí, o storage só responde para quem estiver dentro da VNet ou de redes peered.
"Se você quer restringir o acesso à sua conta de storage apenas pelo private endpoint, configure o firewall do storage para negar ou controlar o acesso pelo endpoint público." (Microsoft Learn, Use private endpoints for Azure Storage, tradução livre)
O problema: como o cliente final faz download?
Aqui aparece o trade-off clássico. Se você fecha o endpoint público completamente, o cliente final, que está no celular dele em casa, não consegue mais usar a URL com SAS para fazer download direto. Ele não está na sua VNet.
Existem três caminhos. O primeiro é manter o endpoint público para download de cliente, mas bloquear tudo o mais (operações de gestão, CI/CD, replicação interna) pelo Private Endpoint. Isso é pragmático e funciona para a maioria dos sistemas de boleto.
O segundo é colocar um Azure Front Door ou Application Gateway na frente do storage, que recebe a requisição pública do cliente, termina o TLS, aplica regras de WAF e DDoS, e faz o download do blob pelo Private Endpoint e retorna ao cliente. Você perde a vantagem de o cliente baixar direto do storage, porque agora o gateway faz esse papel, mas ganha proteção muito mais robusta com WAF centralizado.
O terceiro, para ambientes muito sensíveis, é forçar que o cliente use VPN ou zero-trust network access da empresa para acessar qualquer dado. Isso não é viável para boletos de varejo, mas é adequado para documentos internos ou contratos corporativos.
flowchart LR
subgraph Internet
CLI[Cliente Final]
end
subgraph AzureFront
FD[Azure Front Door
WAF + DDoS Protection]
end
subgraph VNet
APP[Backend Java
Container Apps]
PE[Private Endpoint
10.0.1.5]
end
subgraph Storage
SA[(Azure Blob Storage
Endpoint público
desabilitado)]
end
CLI -->|HTTPS com SAS| FD
FD -->|Private Link| PE
PE --> SA
APP -->|Private Link| PEO Private Endpoint tem cobrança por hora de existência e por gigabyte trafegado. Para volumes pequenos, isso pode pesar proporcionalmente. Para um banco com milhões de boletos por mês, dilui rápido.
"Desabilite todo o tráfego público para a conta de storage." (Microsoft Learn, Architecture Best Practices for Azure Blob Storage, tradução livre)
Quinta camada: Lifecycle Management, porque dado velho custa dinheiro
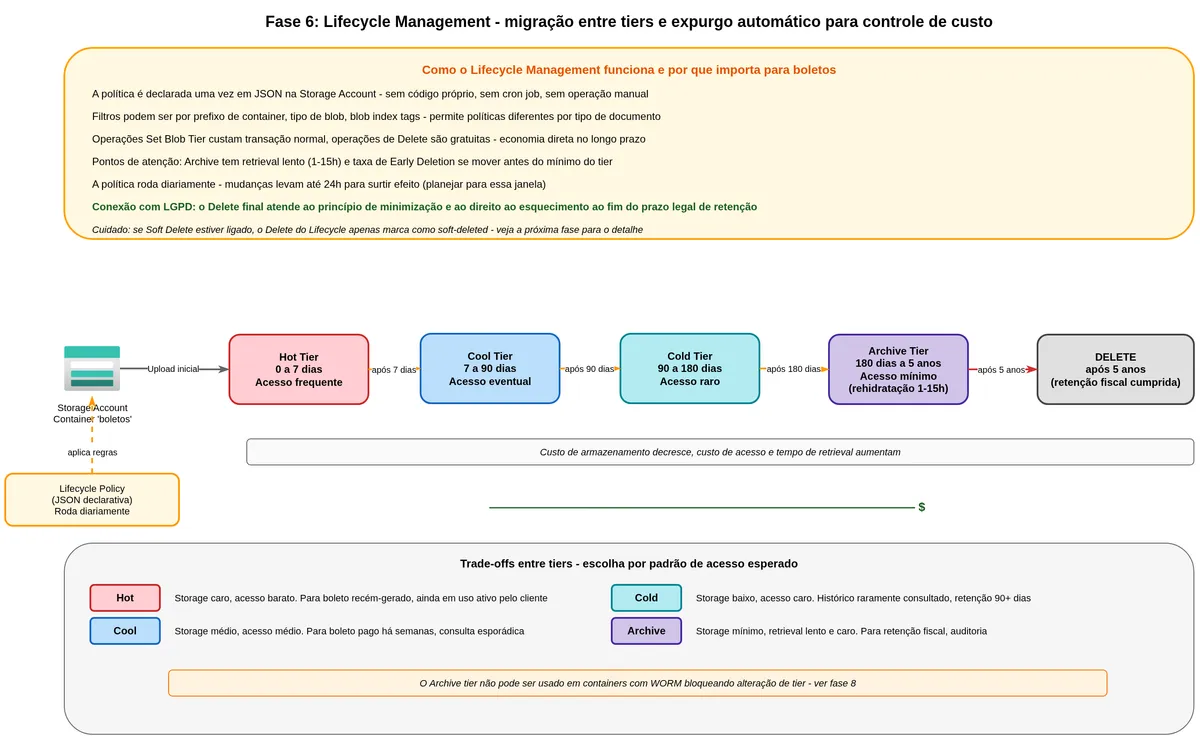
Tudo que armazenamos custa dinheiro mensalmente. E no Azure, o custo por gigabyte varia muito dependendo de quantas vezes você precisa acessar aquele dado. O Azure Blob Storage tem quatro camadas de acesso, e entender o que cada uma representa é o começo para criar uma política de ciclo de vida inteligente.
O que significam as camadas Hot, Cool, Cold e Archive
A camada Hot é para dados acessados frequentemente. O custo de armazenamento é o mais alto, mas o custo de acesso (leitura, listagem) é o mais baixo. Para um boleto recém-gerado que o cliente vai baixar várias vezes nos próximos dias, Hot é a camada correta.
A camada Cool é para dados acessados com pouca frequência, com expectativa de ficarem lá por pelo menos trinta dias. O custo de armazenamento cai, mas o custo por operação de leitura sobe. Para um boleto já pago há dois meses, que o cliente raramente vai consultar, Cool já faz sentido.
A camada Cold foi introduzida mais recentemente e fica entre Cool e Archive. Dados esperados para ficar no mínimo noventa dias, com acesso ainda mais raro. Um boleto de um ano atrás que só é consultado em auditoria ou por demanda do cliente.
A camada Archive é o arquivo morto. O custo de armazenamento é o menor de todos, mas o dado fica "congelado" e não pode ser lido diretamente. Para ler um blob em Archive, você precisa primeiro "reaquecê-lo" (chamado de rehidratação) para Cool ou Hot, o que pode levar de uma a quinze horas. O custo de rehidratação é alto. Archive é adequado para documentos fiscais que precisam existir por obrigação legal mas que raramente alguém vai pedir.
Como o Lifecycle Management funciona
O Lifecycle Management é uma política declarativa em formato JSON que você define na Storage Account. Uma vez configurada, o Azure roda essa política diariamente e move ou apaga blobs conforme as regras. Você não precisa de código, não precisa de job agendado, não precisa de monitoramento manual. A plataforma faz isso por você.
"Ao usar o gerenciamento de ciclo de vida de blob, os clientes podem otimizar custos de forma proativa por meio de políticas baseadas em regras que automaticamente movem dados para tiers mais frios ou os expiram quando não são mais necessários." (Microsoft Learn, Azure Blob Storage lifecycle management overview, tradução livre)
Para boletos, uma política razoável seria:
{
"rules": [
{
"name": "boleto-lifecycle",
"enabled": true,
"type": "Lifecycle",
"definition": {
"filters": {
"blobTypes": ["blockBlob"],
"prefixMatch": ["boletos/"]
},
"actions": {
"baseBlob": {
"tierToCool": { "daysAfterModificationGreaterThan": 7 },
"tierToCold": { "daysAfterModificationGreaterThan": 90 },
"tierToArchive": { "daysAfterModificationGreaterThan": 180 },
"delete": { "daysAfterModificationGreaterThan": 1825 }
}
}
}
}
]
}flowchart LR
H[Hot
0-7 dias
Acesso frequente] --> C[Cool
7-90 dias
Acesso eventual]
C --> CO[Cold
90-180 dias
Acesso raro]
CO --> AR[Archive
180 dias - 5 anos
Acesso mínimo]
AR --> DEL[Deletado
após 5 anos]
style H fill:#ff8a80,color:#000
style C fill:#82b1ff,color:#000
style CO fill:#80d8ff,color:#000
style AR fill:#b388ff,color:#000
style DEL fill:#ccc,color:#000Alguns cuidados importantes. Operações de mudança de tier (Set Blob Tier) têm custo de operação normal. Exclusão não tem custo adicional. Mover um blob para Cool ou Cold antes de trinta ou noventa dias respectivamente gera taxas de "exclusão antecipada". A política roda uma vez por dia, então mudanças podem levar até 24 horas para surtir efeito. E existe uma limitação, a política não consegue apagar blobs com WORM ativo (vamos falar disso a seguir).
"As políticas de gerenciamento de ciclo de vida não têm custo direto. Os clientes pagam o custo padrão de operação para as chamadas da API Set Blob Tier. Operações de exclusão são gratuitas." (Microsoft Learn, Azure Blob Storage lifecycle management overview, tradução livre)
O Lifecycle Management é também o mecanismo pelo qual a empresa cumpre o art. 16 da LGPD. A lei exige que dados pessoais sejam eliminados após o término do tratamento, com exceção dos casos de obrigação legal. Para boletos, o prazo fiscal define essa obrigação. Sem uma política automatizada, o que acontece na prática é acumulação indefinida, porque ninguém tem tempo de fazer exclusão manual, e o dado fica armazenado sem finalidade legal que o justifique. A política configura esse ciclo de forma auditável, transformando uma obrigação legal numa evidência técnica verificável em caso de fiscalização.
Sexta camada: Soft Delete e Versionamento, a rede de segurança contra desastres
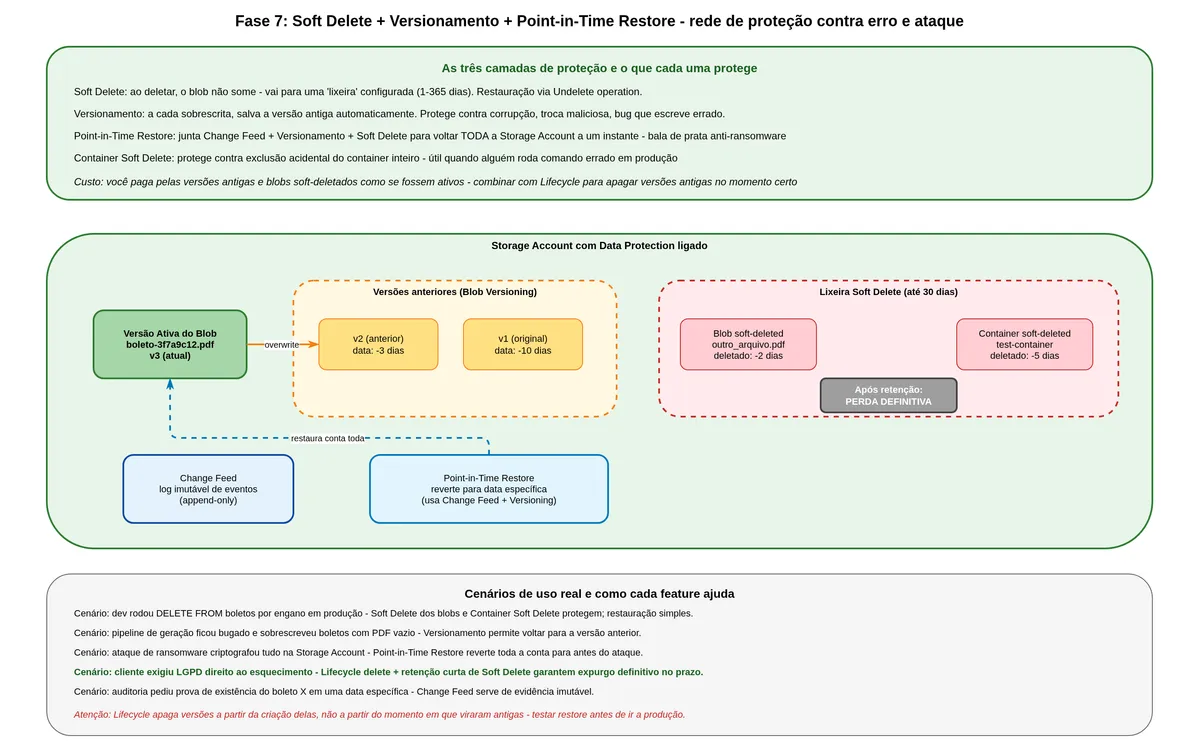
Imagine o seguinte cenário: alguém no time faz deploy de uma versão com bug, e em quarenta minutos cinquenta mil boletos são apagados do storage por engano. Ou um atacante compromete uma identidade e roda exclusão em massa. Sem proteção, é game over. Com Soft Delete, é possível recuperar tudo.
O que é o Soft Delete e como funciona
O Soft Delete é um mecanismo de remoção suave. Quando você deleta um blob com Soft Delete habilitado, o Azure não apaga o dado imediatamente. Ele marca o blob como "soft-deleted" e mantém os bytes por um período configurável (de 1 a 365 dias). O blob desaparece das listagens normais, mas pode ser recuperado com um comando de "Undelete" durante o período de retenção. Depois que o período expira, aí sim o dado some para sempre.
"O soft delete de blob protege um blob individual e suas versões, snapshots e metadados contra exclusões ou sobrescritas acidentais, mantendo os dados excluídos no sistema por um período de tempo definido. Durante o período de retenção, você pode restaurar o blob ao estado em que estava quando foi excluído. Após a expiração do período de retenção, o blob é excluído permanentemente." (Microsoft Learn, Soft delete for blobs, tradução livre)
Pense no Soft Delete como o botão "Lixeira" que você conhece no computador. Quando você deleta um arquivo, ele vai para a lixeira. Enquanto estiver na lixeira, você pode restaurar. Quando você esvazia a lixeira, aí não tem mais volta.
Existe Soft Delete para blobs individuais, e existe Soft Delete para containers inteiros. Os dois funcionam de forma independente e é recomendado habilitar ambos.
O que é o Versionamento e como ele complementa
O Versionamento vai além do Soft Delete. Com ele habilitado, cada vez que você sobrescreve um blob, o Azure automaticamente salva a versão anterior. Cada versão tem um identificador único e você pode acessar, copiar ou promover versões antigas para a versão corrente.
A diferença prática: o Soft Delete protege contra apagar. O Versionamento protege contra apagar e contra sobrescrever. Se alguém substituiu o PDF do boleto por um arquivo corrompido ou malicioso, com Versionamento você consegue restaurar a versão boa.
"A Microsoft recomenda habilitar container soft delete e versionamento de blob em conjunto com o blob soft delete para garantir proteção completa dos dados de blob." (Microsoft Learn, Soft delete for blobs, tradução livre)
Uma armadilha documentada aqui merece atenção. A SingleStore, empresa de banco de dados, publicou um relato de como configurou Versionamento e Soft Delete juntos sem cuidado com a política de lifecycle de versões antigas. O que aconteceu foi que o lifecycle começou a apagar versões a partir da data de criação delas, não da data em que se tornaram versões antigas. Em cenários de recuperação após incidente, descobriram que as versões que esperavam ainda estar disponíveis já haviam sido removidas.
"O Azure conta o tempo para excluir versões anteriores a partir do momento em que elas foram criadas, o que pode levar a incidentes de perda de dados (ou a uma falsa sensação de ter capacidade de recuperar dados)." (SingleStore, Lessons Learned From Using Azure Versioning and Soft-Delete, tradução livre)
A solução é configurar o lifecycle explicitamente para versões antigas com um número de dias suficiente para dar janela de recuperação, e testar o processo de restore antes de confiar nele em produção.
Point-in-Time Restore, quando você precisa voltar no tempo
Se Soft Delete e Versionamento protegem item por item, o Point-in-Time Restore protege toda a conta de uma vez. Ele é uma feature que, quando habilitada junto com change feed, versionamento e soft delete, permite restaurar todos os blobs da conta para o estado que tinham em qualquer instante dentro da janela de retenção configurada.
É sua bala de prata para ataques de ransomware, onde um atacante criptografa ou apaga tudo, ou para bugs catastróficos de migração.
flowchart TB
BL[Blob Atual] -->|Sobrescrita| V1[Versão Anterior 1]
BL -->|Sobrescrita 2| V2[Versão Anterior 2]
BL -->|Delete Acidental| SD[Soft Deleted
até 30 dias]
SD -->|Undelete| BL
PITR[Point-in-Time Restore
Seleciona instante T] -->|Restaura todos os blobs| EST[Estado em T]Habilitar esse conjunto, Soft Delete, Versionamento e Change Feed, tem custo. Você paga pelo armazenamento das versões antigas e dos blobs soft-deletados como se fossem dados normais. Para boletos de baixo volume de alteração (gera uma vez, raramente sobrescreve), o custo extra é pequeno. Para dados frequentemente modificados, pode pesar.
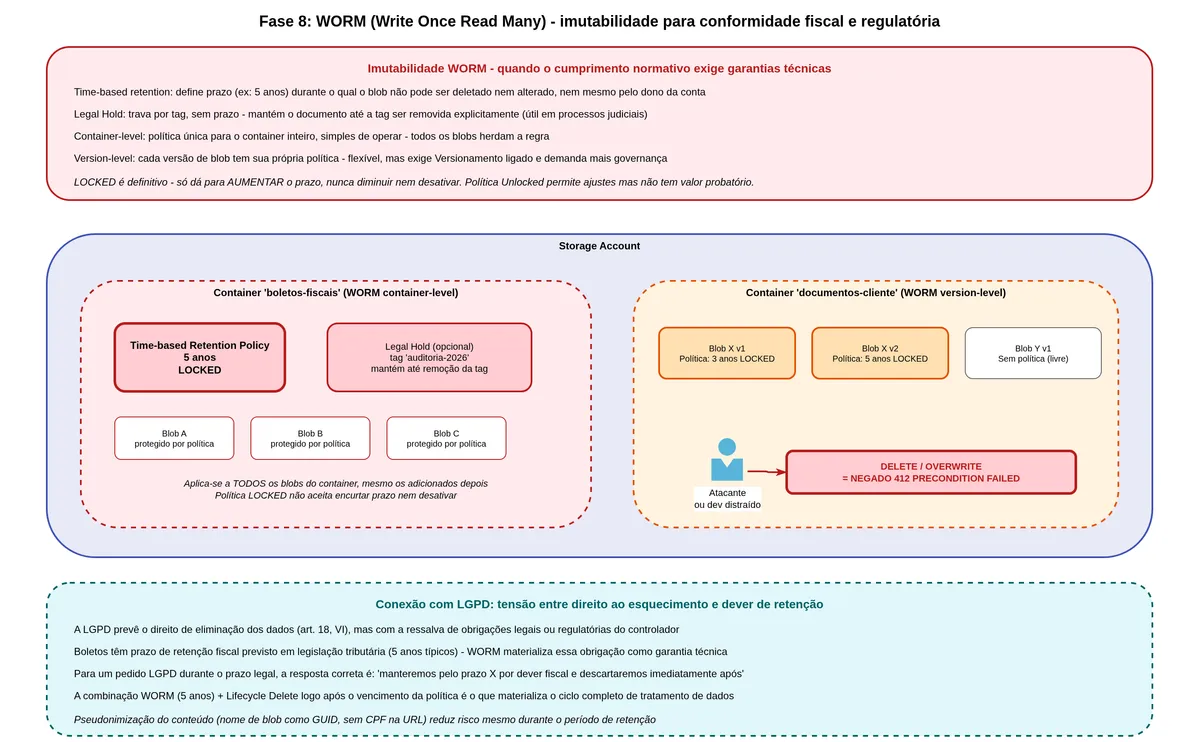
Sétima camada: imutabilidade WORM, a proteção que nem o administrador pode desfazer
Soft Delete e Versionamento protegem contra erros e contra atacantes com acesso limitado. Mas e se o atacante comprometer uma identity com permissão de administrador do storage? Ou se um funcionário interno desonesto tentar apagar evidências? O Soft Delete pode ser desabilitado por quem tem permissão. Versões antigas podem ser explicitamente deletadas.
Para esse nível de ameaça existe a imutabilidade WORM.
O que significa WORM
WORM é a sigla de Write Once Read Many, escrever uma vez e ler muitas vezes. É um modelo em que após salvar, o dado não pode ser modificado nem apagado durante um período determinado, por ninguém. Não pelo desenvolvedor, não pelo administrador da conta, não pelo suporte da Microsoft.
O Azure Blob Storage implementa WORM através de políticas de imutabilidade. Você configura uma política em um container dizendo "qualquer blob neste container fica bloqueado contra modificação e exclusão por X dias a partir da data de criação". Quando essa política é travada (locked), ela não pode ser encurtada, não pode ser removida, só pode ser estendida.
"Quando uma política de imutabilidade está em vigor, os blobs não podem ser modificados nem excluídos até que o período de retenção expire. Nem por usuários, nem por administradores, e nem mesmo pelo suporte da Microsoft." (OneUptime, How to Configure Immutable Storage with WORM Policies, tradução livre)
O Azure valida essa conformidade com organismos regulatórios. A imutabilidade do Azure Blob Storage foi avaliada por uma firma independente especializada em governança de informação, a Cohasset Associates, e foi validada como conforme com as regras de retenção de registros de instituições financeiras.
"A Microsoft contratou uma firma de avaliação independente especializada em gestão documental e governança da informação, a Cohasset Associates, para avaliar o armazenamento imutável para blobs e sua aderência a requisitos específicos do setor de serviços financeiros. A Cohasset validou que o armazenamento imutável, quando usado para reter blobs em estado WORM, atende aos requisitos relevantes de armazenamento da CFTC Rule 1.31(c)-(d), da FINRA Rule 4511 e da SEC Rule 17a-4(f)." (Microsoft Learn, Overview of immutable storage for blob data, tradução livre)
Container-level WORM versus Version-level WORM
Existem dois sabores. O WORM no nível de container aplica a política uniformemente a tudo que está no container. Simples de configurar, menos flexível. O WORM no nível de versão (Version-Level WORM) permite configurar períodos diferentes para blobs ou versões individuais dentro do mesmo container.
Para boletos, o design adequado seria um container com WORM no nível de versão habilitado e uma política padrão de cinco anos de retenção. Quando um novo boleto é gerado, ele herda automaticamente os cinco anos. Se houver casos específicos com retenção diferente (boleto de produto com prazo maior), é possível definir a política no nível do blob específico.
Uma armadilha importante: nunca travar uma política sem testar antes. O processo é: criar a política em estado "unlocked" (desbloqueado), testar a expiração, validar que o período está correto, e só então "lock" (travar). Uma vez travada, não tem volta. Você pode estender, mas não pode encurtar nem remover.
flowchart LR
UP[Upload do Boleto] --> CT[Container WORM
Version-Level]
CT -->|Política padrão
5 anos| BL[Blob Imutável]
BL -->|Lifecycle move tier
sem deletar| AR[Blob em Archive
ainda imutável]
AR -->|Após 5 anos
policy expira| FREE[Pode ser deletado
pelo lifecycle]E aqui há uma interação importante com o lifecycle: a política de lifecycle pode mover blobs entre camadas (Hot, Cool, Archive) mesmo com WORM ativo, mas não pode deletar o blob enquanto a política de retenção estiver em vigor. O delete do lifecycle só acontece depois que a retenção WORM expirar.
O trade-off de custo aqui é genuíno. Com WORM de cinco anos, você está comprometido a pagar armazenamento por cinco anos independente de cancelamento de contrato, inadimplência do cliente, ou qualquer evento de negócio. Para um banco regulado, isso é aceito. Para uma startup em fase de produto, pode ser impeditivo.
O WORM materializa a resposta técnica para a tensão entre o direito de eliminação do titular (art. 18, VI) e a obrigação legal de retenção (art. 16). A impossibilidade técnica de deletar antes do prazo travado é a prova de que a empresa está cumprindo a obrigação, não ignorando o pedido. O Lifecycle Delete encadeado materializa o expurgo no momento em que a retenção legal expira, fechando o ciclo.
Oitava camada: criptografia em repouso e em trânsito
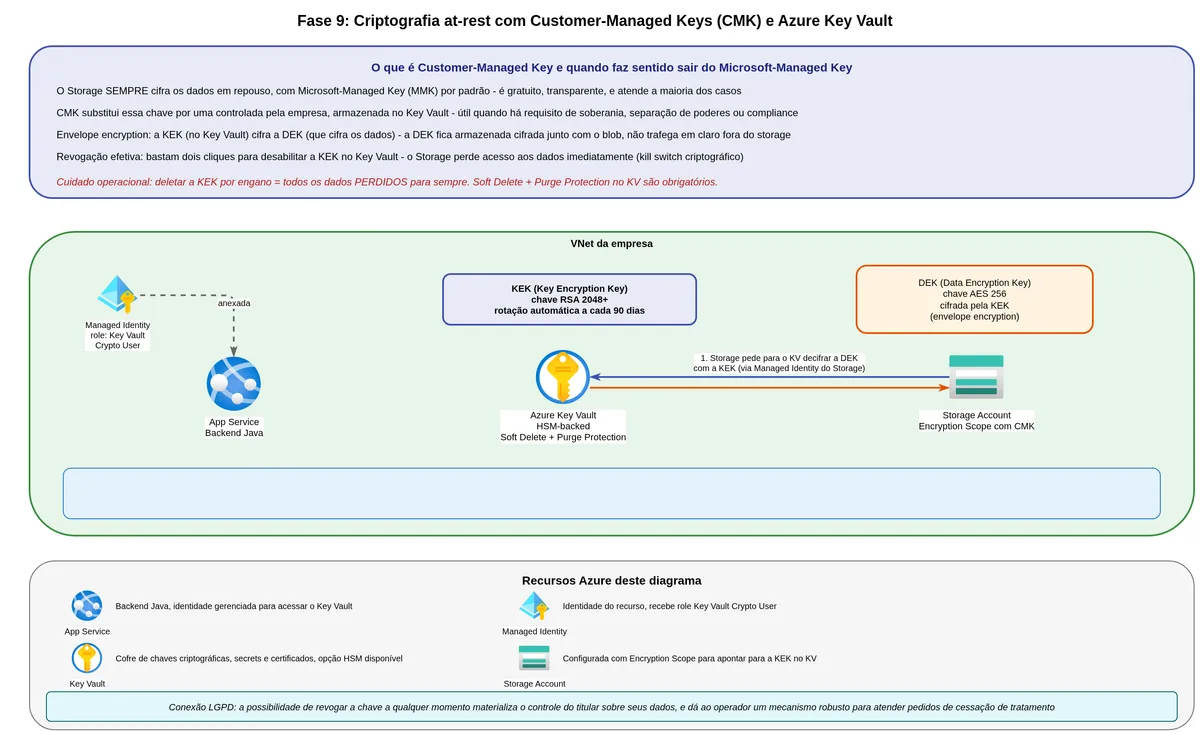
Já falamos sobre quem pode acessar (autenticação), o que pode fazer (autorização), e por quanto tempo o dado fica disponível (lifecycle e retenção). Agora vamos falar sobre como o dado é protegido enquanto está guardado e enquanto está em movimento.
Criptografia em repouso: o que acontece com os bytes no disco
O Azure Storage criptografa todo dado em repouso por padrão, usando AES-256. Isso significa que os bytes do PDF do boleto, quando gravados nos discos físicos dentro dos datacenters da Microsoft, estão cifrados. Mesmo que alguém fisicamente retirasse um disco, não conseguiria ler os dados sem a chave.
"Todos os recursos do Azure Storage são criptografados, incluindo blobs, discos, arquivos, queues e tabelas. Todos os metadados de objeto também são criptografados. Não há custo adicional para a criptografia do Azure Storage." (Microsoft Learn, Azure Storage encryption for data at rest, tradução livre)
Por padrão, as chaves que cifram os dados são gerenciadas pela Microsoft. A Microsoft as rotaciona automaticamente conforme políticas internas de segurança. Para a maioria dos casos, isso é suficiente.
Para ambientes com requisitos regulatórios específicos, existe a opção de Customer-Managed Keys (CMK). Nesse modelo, você cria a chave no Azure Key Vault (ou no Key Vault Managed HSM, que é FIPS 140-2 Level 3) e instrui o Storage a usá-la para criptografar a chave-mestra dos dados. Esse processo usa envelope encryption: a chave da Microsoft envolve os dados, e a sua chave envolve a chave da Microsoft.
A vantagem prática do CMK é o controle total. Se você desabilitar ou deletar a chave no Key Vault, os dados ficam imediatamente inacessíveis. Isso serve como "kill switch" em casos extremos como ordens judiciais ou comprometimento grave do ambiente.
"Quando você configura customer-managed keys para uma conta de storage, o Azure Storage envelopa a chave de criptografia raiz da conta com a customer-managed key armazenada no key vault ou managed HSM associado." (Microsoft Learn, Customer-managed keys for account encryption, tradução livre)
O custo de CMK é a complexidade operacional. Você precisa gerenciar o Key Vault corretamente, habilitar soft delete e purge protection nele, configurar RBAC adequado, e ter monitoramento de expiração de chaves. Um Key Vault mal operado pode causar indisponibilidade total do storage se a chave ficar inacessível.
Criptografia em trânsito: protegendo o dado enquanto viaja
Quando o cliente faz download do boleto via URL com SAS, os bytes viajam pela rede. Para garantir que ninguém intercepte esses bytes no caminho, o Azure Storage suporta TLS (Transport Layer Security) e pode ser configurado para exigir HTTPS em todas as chamadas.
A configuração relevante na Storage Account é a propriedade "Secure transfer required". Com ela habilitada, qualquer requisição via HTTP simples é rejeitada com erro 400. Só HTTPS passa.
E no SAS token, conforme mostramos no código, o parâmetro SasProtocol.HTTPS_ONLY garante que o tíquete de acesso só funciona sobre HTTPS. Mesmo que alguém construa uma URL com SAS e tente usar via HTTP, o Azure rejeita.
Criptografia em repouso e em trânsito é o piso técnico esperado pela ANPD em qualquer fiscalização envolvendo dados financeiros, cobrindo o art. 46 da lei. Em caso de incidente, dado vazado mas criptografado adequadamente tem impacto reportado menor, porque o atacante tem os bytes mas não o significado deles. Quando se opta por CMK, há uma vantagem adicional que vai além da criptografia padrão: revogar a KEK no Key Vault torna os dados ilegíveis de imediato, sem precisar operar individualmente cada blob no storage. Esse mecanismo é o único que permite descontinuação criptográfica do acesso em tempo real.
Nona camada: monitoramento, auditoria e Defender for Storage
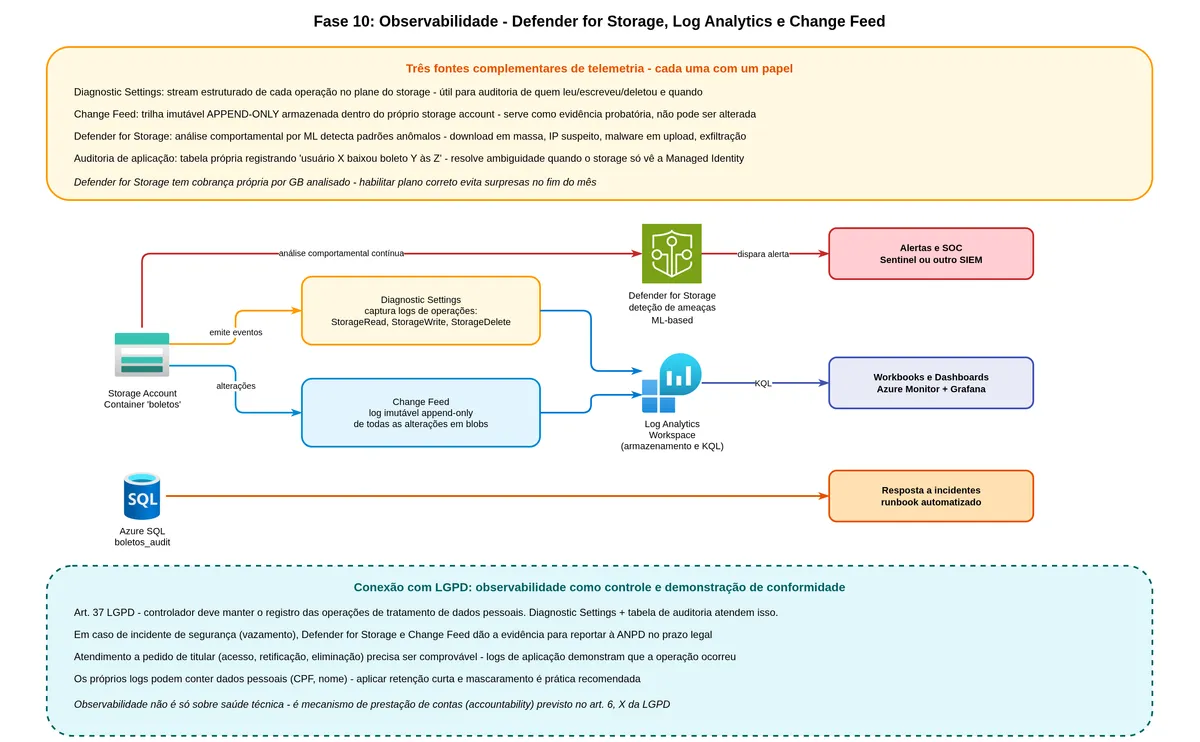
Toda a proteção que construímos até aqui assume que alguém está olhando se algo está fora do padrão. Sem observabilidade, você pode ter todas as camadas de segurança e só descobrir uma brecha quando o dano já foi feito.
O que são os Diagnostic Logs e o que eles registram
O Azure Storage pode ser configurado para enviar todos os seus logs de operação para um workspace do Log Analytics ou para um Event Hub. Esses logs registram cada chamada de API feita ao storage: quem fez (qual identidade ou IP), o que pediu (operação, blob alvo), quando foi, quanto demorou, qual foi o código de retorno, e o tamanho de dados transferidos.
Com esses logs no Log Analytics, você consegue construir consultas Kusto (a linguagem de query da Azure) para detectar padrões suspeitos: muitas leituras em sequência de blobs de clientes diferentes, uploads de blobs muito grandes fora do horário comercial, tentativas de acesso com token inválido.
O que é o Microsoft Defender for Storage
O Defender for Storage é um serviço gerenciado de detecção de ameaças que analisa o padrão de operações do storage usando machine learning e inteligência de ameaças da Microsoft. Ele detecta automaticamente situações como upload de arquivo com assinatura de malware, acesso suspeito de um endereço IP que aparece em listas de ameaças, padrão de exfiltração de dados (muitos downloads em curto período), geração anômala de SAS tokens.
Para cada ameaça detectada, o Defender emite um alerta com detalhes do que foi encontrado, qual o risco potencial, e quais são os próximos passos recomendados.
O que é o Change Feed e por que ele é diferente de um log
O Change Feed é uma feature específica do Azure Blob Storage que registra de forma imutável e ordenada todas as mudanças (criação, modificação, exclusão) que acontecem nos blobs. Diferente dos logs de diagnóstico, que são orientados a requisições de API, o Change Feed é orientado a eventos de dado.
A grande utilidade do Change Feed para boletos é como evidência de custódia. Se alguém questionar "esse boleto existia mesmo naquela data?", o Change Feed diz "sim, aqui está o evento de criação dele, com timestamp, tamanho e hash". Isso é valioso em auditorias e em disputas regulatórias.
flowchart LR
SA[Storage Account] --> DS[Diagnostic Settings]
DS --> LA[Log Analytics
Consultas Kusto]
SA --> CF[Change Feed
Eventos imutáveis]
SA --> DEF[Defender for Storage
ML e inteligência]
DEF --> AL[Alertas automáticos]
CF --> AUD[Auditoria e custódia]
LA --> MON[Dashboards e alertas customizados]Observabilidade tem ligação direta com o art. 37, que obriga o controlador a manter registro das operações de tratamento, e com o art. 48, que obriga comunicação de incidente com identificação dos titulares afetados. Sem Defender for Storage e Change Feed, dimensionar a extensão de um incidente para reportar à ANPD fica inviável. Um ponto que costuma ser ignorado: os próprios logs contêm dado pessoal, então merecem retenção mais curta que o storage primário e RBAC restrito de leitura.
Cruzando com a OWASP API Security Top 10
A OWASP (Open Worldwide Application Security Project) é uma fundação sem fins lucrativos que mantém listas das vulnerabilidades mais comuns em software. A lista mais conhecida é a OWASP Top 10 para aplicações web, mas existe também a versão específica para APIs, atualizada em 2023, que é o que vamos usar aqui. Os autores olham incidentes reais reportados em programas de bug bounty, CVEs publicados e pentests, e classificam por frequência e impacto quais classes de problema mais aparecem.
Dos dez itens da lista de 2023, cinco têm incidência direta no modelo que construímos: API1 (autorização por objeto), API2 (autenticação), API4 (consumo de recursos), API7 (SSRF) e API8 (misconfiguration). Os demais, API3, API5, API6, API9 e API10, tratam de autorização por propriedade de objeto, controle de acesso por nível de função, limitação de fluxos de negócio sensíveis, gestão de inventário de APIs e consumo seguro de APIs externas. Essas classes se aplicam ao design de endpoints REST e ao controle de permissão por perfil de usuário, que ficam fora do escopo de armazenamento abordado aqui. Para cada item coberto, a análise segue a mesma sequência: a vulnerabilidade, como o ataque acontece na prática, e como a arquitetura responde.
API1, Broken Object Level Authorization (BOLA). É a vulnerabilidade mais comum em APIs REST. Acontece quando o sistema autentica o usuário (sabe quem ele é) mas não autoriza no nível do objeto que está sendo acessado (não confere se aquele usuário pode acessar aquele objeto específico). O ataque típico é trocar o ID na URL. O usuário João, autenticado, faz GET em /boletos/123 e recebe seu próprio boleto. Em seguida, troca para /boletos/124 e recebe o boleto da Maria, que era visível pela API porque o backend só verificou que João estava autenticado, sem checar que o boleto 124 não era dele. É também conhecido como IDOR (Insecure Direct Object Reference) e é responsável por uma grande parte dos vazamentos massivos de dados em APIs nos últimos anos.
"Todo endpoint de API que recebe um identificador de objeto, e executa qualquer ação sobre esse objeto, deve implementar verificação de autorização em nível de objeto. A verificação precisa validar que o usuário autenticado tem permissão para executar a ação solicitada sobre o objeto solicitado." (OWASP API Security, API1:2023 Broken Object Level Authorization, tradução livre)
API2, Broken Authentication. Aqui a falha está no mecanismo de autenticação propriamente dito. Pode ser senha fraca, token JWT mal validado, ausência de expiração, segredo fixo no código, mecanismo de refresh quebrado, ou autenticação que aceita assinatura inválida. A consequência é que o atacante consegue se passar pelo usuário, ou pior, pelo sistema inteiro. O caso da Microsoft com o SAS de cinquenta anos de validade é desse tipo. Não tinha nada errado tecnicamente com a credencial, mas o mecanismo de autenticação aceitava um token sem validade prática, o que equivale a não ter autenticação. Outro caso comum é o segredo da aplicação publicado por engano em repositório Git, e atacantes que monitoram o GitHub em tempo real descobrem em minutos.
API4, Unrestricted Resource Consumption. Antes era conhecido como rate limiting issues. A ideia é que toda API consome recursos (CPU, memória, rede, custo de operação), e se o sistema não impõe limite ao consumo, o atacante consegue derrubá-lo, ou pior, fazer a empresa pagar uma fatura gigante. Em sistemas baseados em consumo, como funções serverless ou storage cobrado por operação, esse é um problema duplo, porque além da indisponibilidade, há custo direto. Um atacante pode forçar geração de boleto em loop, fazer download repetido, ou disparar listagem de container, gerando despesa real.
API7, Server-Side Request Forgery (SSRF). Aqui o atacante explora uma funcionalidade legítima da aplicação que faz requisições HTTP para URLs fornecidas externamente. Imagine que o backend tem uma feature de "buscar logo do banco emissor a partir desta URL". O atacante envia como URL não o site público de um banco, mas o endpoint do IMDS (Instance Metadata Service) onde os recursos Azure pegam o token da Managed Identity. Se o backend faz a requisição sem validar, ele acaba retornando ao atacante o token JWT da própria Managed Identity. Daí pra exfiltrar dados ou se mover lateralmente é só usar o token como qualquer chamada autenticada faria. Foi exatamente o vetor do incidente da Capital One em 2019. A aplicação rodando na AWS tinha permissão de fazer requisições HTTP para URLs externas como parte do fluxo normal. Um ex-funcionário da AWS explorou essa capacidade enviando como URL o endpoint de metadados da instância EC2. O token retornado deu acesso a mais de 700 buckets S3 com dados de mais de cem milhões de clientes norte-americanos e canadenses. A Capital One pagou 80 milhões de dólares em acordo regulatório.
"Defenda-se contra roubo ou abuso de credenciais. Por exemplo, na AWS, exija o uso de IMDSv2 e bloqueie a saída para o IP de metadata link-local (169.254.169.254) a partir de containers e funções." (Wiz, OWASP API Security Top 10 Risks, tradução livre)
API8, Security Misconfiguration. Esse é o "guarda-chuva" para configuração errada que abre o sistema. Container público que não devia ser, TLS opcional, header de segurança ausente, CORS com *, endpoint de debug exposto em produção, versão de software desatualizada, política de senha permissiva. A maioria dos vazamentos públicos cai aqui, não porque o atacante seja sofisticado, mas porque alguma configuração ficou frouxa por engano ou por pressa.
Como a arquitetura conversa com a LGPD do começo ao fim
Antes do mapeamento técnico, dois pontos de partida que a maioria dos textos pula.
O primeiro é identificar os papéis. Numa fintech que emite boleto próprio, a empresa é o controlador, que define as finalidades e os meios do tratamento. Se a emissão passa por um processador externo, esse processador é o operador e precisa de um contrato de processamento nos termos do art. 39 da lei. O Blob Storage e os demais serviços Azure são suboperadores, e a Microsoft documenta isso no DPA (Data Processing Agreement) disponível no Portal de Confiança de Serviços.
O segundo ponto é a base legal. A LGPD exige que todo tratamento de dado pessoal tenha uma base do art. 7, e para boleto bancário há duas que se aplicam conforme a fase do ciclo de vida. Durante o período de atividade do boleto, antes do vencimento e até a quitação, a base aplicável é execução de contrato (art. 7, V): o boleto é o instrumento de cobrança vinculado a uma relação contratual com o pagador. Depois do pagamento, quando o dado precisa ser mantido por prazo fiscal, a base passa a ser cumprimento de obrigação legal (art. 7, II). Para fins tributários e regulatórios, esse prazo é tipicamente cinco anos. Essa distinção importa porque a base legal condiciona o prazo de retenção justificável, e o prazo justificável é o que o Lifecycle Management deve refletir. Sem essa ancoragem legal, qualquer prazo configurado no Lifecycle é arbitrário e indefensável em fiscalização.
"A presente Lei dispõe sobre o tratamento de dados pessoais (...) com o objetivo de proteger os direitos fundamentais de liberdade e de privacidade e o livre desenvolvimento da personalidade da pessoa natural." (Lei nº 13.709/2018, art. 1º)
Com papéis e bases legais definidos, o vínculo entre cada decisão técnica e o princípio da lei que ela atende se torna verificável.
O princípio da finalidade (art. 6, I) se materializa no escopo do SAS token. O tíquete emitido permite leitura de um blob específico por quinze minutos. Não é possível usar a mesma URL para escrever, listar ou apagar. O escopo mínimo do tíquete é o piso técnico da finalidade declarada: o dado só é acessível para a operação que o motivou.
O princípio da necessidade (art. 6, III) aparece em dois pontos. Na separação metadata-conteúdo: quando o sistema consulta o status de um boleto, acessa só o banco de metadados, sem tocar no PDF que carrega os dados pessoais completos do pagador. E no Lifecycle Management, que garante que boletos fora do prazo legal sejam deletados automaticamente. Sem essa política, o que acontece na prática é acumulação indefinida de dados pessoais porque ninguém tem tempo de fazer exclusão manual.
O princípio da segurança (art. 6, VII e art. 46) se materializa na soma das camadas, não em uma feature isolada. Managed Identity elimina o vetor de vazamento por credencial estática. Private Endpoint tira o tráfego da internet pública. Criptografia AES-256 em repouso e TLS obrigatório em trânsito protegem os bytes. RBAC restringe quem pode fazer o quê. Nenhuma dessas camadas sozinha cobre o art. 46, mas o conjunto corresponde ao que o Guia de Segurança da ANPD lista como medidas técnicas adequadas para dados financeiros.
O princípio da prestação de contas (art. 6, X) depende de combinação de camadas para ser exercido. Diagnostic Settings exportando logs para Log Analytics, Change Feed registrando evento a evento o que aconteceu com cada blob, e a tabela de auditoria da aplicação registrando quem pediu qual boleto e quando formam uma trilha que permite, em caso de fiscalização, mostrar evidência de que o sistema operou conforme as regras. Sem essa trilha, cumprir o art. 48 (notificação de incidente à ANPD com descrição da extensão do vazamento) fica inviável, porque sequer é possível identificar quais titulares foram afetados.
O ponto de maior tensão com a lei aparece no cruzamento entre o direito de eliminação do titular (art. 18, VI) e a ressalva do art. 16. Quando um titular pede a exclusão do seu dado antes de expirar o prazo fiscal, a empresa não é obrigada a atender, mas precisa responder informando que o dado será mantido pelo prazo legal e descartado assim que esse prazo termine. O WORM com política travada torna essa promessa verificável: não é possível deletar antes do prazo fixado, nem pelo administrador, nem pelo time de suporte, nem por quem processar um pedido de titular de forma equivocada. O Lifecycle Delete encadeado materializa o expurgo no momento exato em que a retenção legal expira.
Vale um cuidado sobre os logs de diagnóstico e a tabela de auditoria: eles contêm dado pessoal. Merecem retenção mais curta que o storage primário, RBAC de leitura restrito a quem opera segurança, e revisão periódica de quais campos precisam estar registrados.
Por fim, cumprir a LGPD nessa arquitetura não se resume a configurar as features certas. A lei pede documentação: Aviso de Privacidade descrevendo como e por quanto tempo os dados são tratados, RIPD mapeando os riscos específicos do processamento de dados de pagamento, e contrato de processamento com cada operador envolvido. A arquitetura dá a base material para sustentar esses documentos, mas eles precisam ser construídos pela área jurídica junto com o time técnico.
Cenários de falha documentados que vale conhecer
A teoria fica mais clara quando a gente olha os erros reais que outras empresas cometeram. A seção a seguir lista cinco padrões de falha que aparecem com frequência em pentests, post-mortems e relatórios de incidente. Cada um explica como o problema acontece, qual o impacto típico, e como o desenho que construímos no texto previne ou atenua.
Chave esquecida no repositório
O cenário é o seguinte. O desenvolvedor cria o arquivo application.properties com a connection string do storage (que contém a Shared Key) durante o desenvolvimento local. Na hora de subir o código para o Git, o .gitignore não estava configurado, ou o arquivo já tinha sido commitado antes da regra entrar em vigor. O segredo vai parar no histórico público do repositório. Bots automatizados que monitoram o GitHub em tempo real, escaneando milhões de commits por dia em busca de tokens AWS, chaves Azure e credenciais Slack, encontram a chave em minutos. Daí até o atacante descobrir que tipo de dado a conta tem e exfiltrar é questão de horas.
O caso da Microsoft com os 38 TB seguiu uma variação desse padrão, com SAS em vez de chave de conta direta, mas o ponto comum é o mesmo. Credencial estática com permissão ampla acaba escapando do repositório onde deveria viver e cai em mãos erradas. A rotação manual depois do incidente é dolorosa, porque toda aplicação que usava aquela chave precisa ser atualizada simultaneamente.
A defesa estrutural que aplicamos é eliminar o conceito de credencial estática. Com Managed Identity, simplesmente não existe segredo para vazar. O token é solicitado em runtime, dura cerca de uma hora, e o atacante que roubar o código fonte não vai encontrar nada utilizável. Como camada extra, scanning de segredo no pipeline (GitHub Secret Scanning, Gitleaks, TruffleHog) bloqueia o commit antes de chegar no repositório remoto. E desabilitar Shared Key na conta inteira (allowSharedKeyAccess=false) garante que mesmo uma chave histórica vazada não funciona mais.
Container público que ninguém percebeu
O dev está com pressa de demonstrar uma funcionalidade. O CORS está bloqueando, o navegador reclama de autenticação, e a apresentação é em vinte minutos. Solução rápida, marcar o container como público, mostrar a demo, voltar depois e reverter. Só que "depois" não acontece. A demo passa, o ticket é fechado, o time muda de prioridade, e o container fica público por semanas, ou meses. Boletos que deveriam estar protegidos ficam expostos a qualquer pessoa que descubra o nome da Storage Account, e existe gente fazendo varredura de subdomínios *.blob.core.windows.net exatamente buscando containers públicos.
Esse padrão é tão comum que existem ferramentas dedicadas (BlobHunter, GrayhatWarfare) que indexam buckets e containers públicos da internet inteira. Os achados viram manchete de jornal com alguma frequência, normalmente envolvendo dados de saúde, financeiros ou jurídicos.
A defesa que aplicamos é Azure Policy em nível de subscription bloqueando allowBlobPublicAccess=true. A política não confia em revisão de PR e nem em treinamento de time, ela simplesmente recusa o deploy de qualquer recurso que tente habilitar acesso público. Combinado com Private Endpoint e firewall do storage com defaultAction=Deny, mesmo que alguém burle a Azure Policy de algum jeito criativo, a porta da rede continua fechada para a internet.
Listagem como busca
O time montou o sistema sem banco de dados para os metadados, achando que ia simplificar. Para encontrar boletos de um cliente específico, faz listagem do container filtrando por prefixo. Funciona com mil blobs, demora meio segundo. Funciona com cem mil blobs, demora dez segundos. Vai funcionando até estourar timeout em produção, ou até o time perceber que cada listagem está custando dinheiro porque conta como operação. Em volume real, a fatura do storage cresce de forma desproporcional ao volume de dado armazenado, porque a maior parte do gasto vem de operações, não de bytes.
Pior, a listagem é uma operação inerentemente cara em qualquer storage de objeto. O Azure Blob Storage usa namespace plano, o que significa que listar com prefixo é uma operação O(n) sobre o índice do container. Não tem otimização possível por parte do operador, é como funciona arquiteturalmente.
A defesa que aplicamos é a separação metadata-banco-blob desde o dia um. O banco de dados tem índices nas colunas que serão consultadas (cliente_id, vencimento, status), e essas consultas são O(log n) com performance previsível. O blob fica acessível por nome direto (já conhecido pelo banco), nunca por listagem. O custo de operação cai para o mínimo necessário, e a performance fica estável independente do volume acumulado.
Versões sendo apagadas antes do esperado
O time configurou o lifecycle para manter versões antigas por 90 dias, achando que isso significava 90 dias depois da versão virar antiga. Ocorreu um incidente, alguém precisou recuperar uma versão de 60 dias atrás, e as versões já tinham desaparecido. O motivo foi sutil. O Azure conta o prazo de retenção de versão a partir da data de criação da versão, não a partir do momento em que ela deixou de ser a versão atual. Uma versão criada há 100 dias e que virou versão antiga há apenas 10 dias, na contabilidade do Azure tem 100 dias de vida e foi excluída pela política dos 90 dias.
"O Azure conta o tempo para excluir versões anteriores a partir do momento em que elas foram criadas, o que pode levar a incidentes de perda de dados (ou a uma falsa sensação de ter capacidade de recuperar dados)." (SingleStore, Lessons Learned From Using Azure Versioning and Soft-Delete, tradução livre)
A defesa começa pela compreensão correta da semântica antes de configurar. Documente claramente que a janela é desde a criação, não desde a transição para "versão antiga". Configure prazo suficiente considerando a vida útil esperada do blob ativo. Teste a recuperação de versão em ambiente de homologação com volume similar ao de produção, simulando o cenário de incidente. E mantenha runbook documentado de como executar a recuperação, incluindo os comandos exatos, para que o time não esteja descobrindo no Google enquanto está com pressão de incidente em curso.
WORM travado com período errado
O time está fazendo o setup do WORM pela primeira vez. Aplica a política de retenção, configura para "5 anos", clica em "Lock". Só que confundiu unidade na configuração e travou em "5 dias" em vez de "5 anos". Resultado, política travada não pode ser reduzida, mas pode ser aumentada. Então a empresa pode aumentar a retenção, mas se quisesse reduzir os dados não retidos pelo prazo correto, não tem como. Pior, qualquer blob criado naquele container nos próximos 5 dias terá apenas essa janela de proteção, e todo o setup de conformidade fica comprometido até detectar o erro e refazer a política para os blobs novos.
Esse erro é particularmente cruel porque o WORM foi projetado exatamente para impedir reversão. A imutabilidade que protege contra ataque também protege contra erro humano honesto.
A defesa começa pelo workflow de aprovação. Toda política WORM deveria passar por dois pares antes de ser travada, conforme princípio de segregação de funções. Aplique a política como Unlocked primeiro, observe o comportamento durante uma janela definida, simule recuperação e validação, só então rode o Lock. Use Infrastructure as Code (Bicep, Terraform) para que a configuração seja explícita, versionada e revisada em PR, em vez de ser feita no portal manualmente. E mantenha containers separados para teste e para produção, com nomes claros que evitem confusão visual durante a operação.
O fantasma do vendor lock-in
Depois de nove camadas usando features específicas do Azure, é honesto perguntar: o quanto estamos comprometidos com esse provedor?
A resposta precisa separar duas categorias de dependência. A primeira é operacional: você usou o portal do Azure para configurar tudo manualmente, não tem código declarativo, e migrar exigiria reconfigurar cada recurso em outro provedor a partir de um esforço de mapeamento. Esse tipo de dependência é evitável. Infrastructure as Code com Bicep ou Terraform documenta cada configuração como código versionado, e a maioria dos recursos tem equivalente em outros provedores: Object Storage em S3 ou GCS, Private Endpoint em VPC Endpoint ou Private Service Connect, WAF em CloudFront ou Cloud Armor.
A segunda é dependência de comportamento: serviço com características específicas que não têm equivalente direto fora do Azure. O WORM do Azure Blob Storage foi avaliado e certificado pela Cohasset Associates para conformidade com as regras da CFTC, FINRA e SEC. Esse atestado de conformidade é específico da Microsoft e não é transferível para outro provedor sem novo processo de validação. O Change Feed tem uma semântica de log imutável e ordenado com schema próprio. O Defender for Storage usa inteligência de ameaças da própria Microsoft que não está disponível em outros provedores. Se esses controles estiverem documentados no RIPD como requisitos de conformidade, uma migração deixa de ser uma decisão de infraestrutura e passa a ser uma decisão regulatória.
Para a maioria das empresas, a abordagem prática não é multi-cloud nativo, que exige manter infraestrutura paralela em dois provedores ao custo de uma equipe maior e configurações duplicadas. A abordagem que reduz risco sem dobrar complexidade é isolar o domínio da aplicação da infraestrutura de storage desde o início:
public interface BoletoStorage {
void store(String id, byte[] pdf);
String generateDownloadUrl(String id);
void delete(String id);
}
public class AzureBlobBoletoStorage implements BoletoStorage {
// implementação Azure
}Com esse contrato, o domínio nunca depende diretamente de BlobServiceClient. A troca de provedor é uma decisão de infraestrutura confinada nas classes de implementação de cada interface, não espalhada pela lógica de aplicação.
Manter um plano de saída documentado significa listar, em algum lugar versionado: quais features sem equivalente direto estão em uso, qual a dependência regulatória de cada uma, e qual seria o caminho hipotético de migração se o provedor mudar de preço, descontinuar um serviço, ou se a empresa precisar atender um cliente que proíbe Azure. Esse documento não precisa ser um projeto executável, precisa ter informação suficiente para que uma decisão de migração possa ser feita com números verificáveis em vez de suposições.
Composição final: o desenho completo
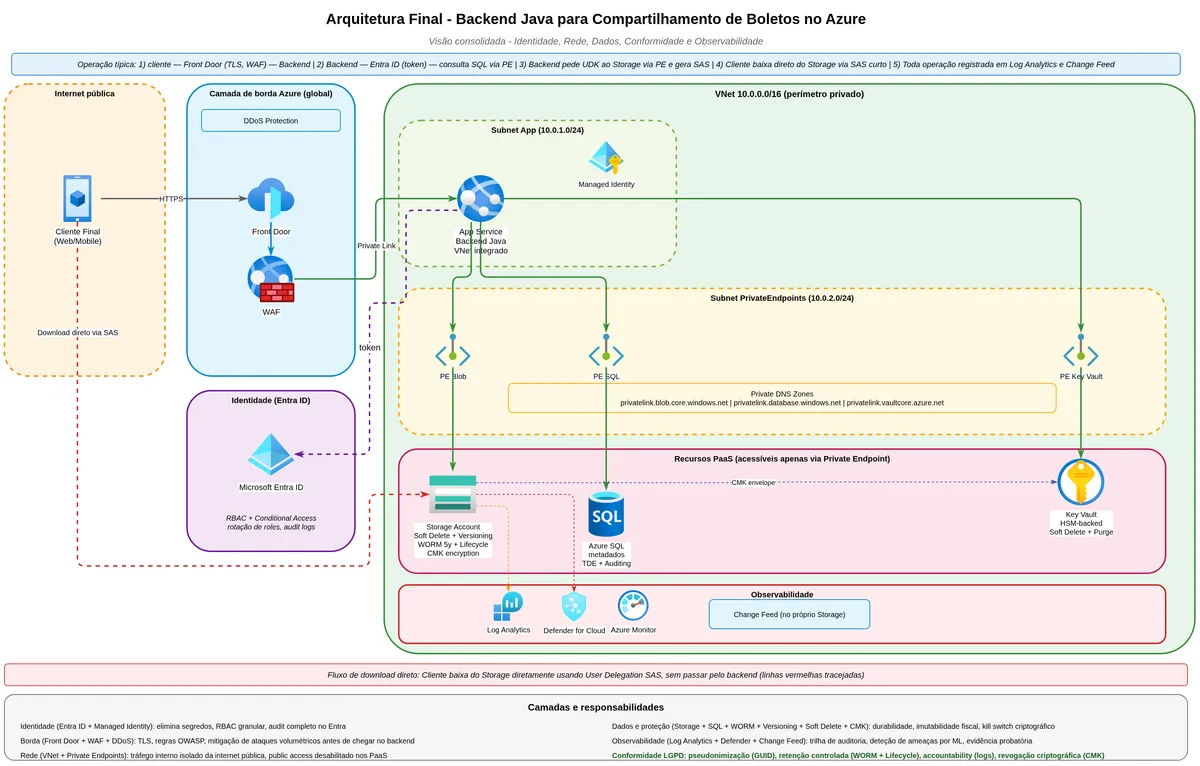
Partimos de um serviço com uma connection string carregando a chave administrativa da conta inteira. Cada camada que adicionamos corrigiu uma classe de problema com incidente documentado associado. Managed Identity eliminou a credencial estática que a Orca Security mostrou virar vetor de execução remota de código. User Delegation SAS trocou a URL permanente pelo tíquete de acesso descartável, corrigindo a classe de problema que causou o vazamento de 38TB na Microsoft. O banco de dados com ACL resolveu o BOLA da OWASP. O Private Endpoint tirou o storage da internet pública. Lifecycle Management criou o mecanismo de descarte automático que a LGPD exige. Soft Delete e Versionamento adicionaram recuperabilidade contra erros e ataques. WORM formalizou a imutabilidade regulatória. CMK deu à empresa controle direto sobre a chave-mestra. Monitoramento com Defender e Change Feed fechou a trilha de auditoria.
A arquitetura consolidada fica assim:
flowchart TB
subgraph Internet
CL[Cliente Final]
end
subgraph FrontEdge[Camada de Borda]
FD[Azure Front Door
WAF + Proteção DDoS]
end
subgraph VNet[Rede Virtual da Empresa]
APP[Backend Java
App Service
Managed Identity]
DB[(Azure SQL
Metadados e ACL)]
KV[Azure Key Vault
CMK opcional]
end
subgraph StorageLayer[Camada de Storage]
SA[(Container: boletos
WORM 5 anos
Soft Delete 30 dias
Versioning ON)]
LOG[Diagnostic Logs]
DEF[Defender for Storage]
CF[Change Feed]
end
subgraph Obs[Observabilidade]
LA[Log Analytics]
AL[Alertas]
end
CL -->|HTTPS| FD
FD -->|Private Link| APP
APP -->|User Delegation Key
gera SAS| SA
CL -->|Download direto
via SAS| SA
APP <-->|Metadados, ACL,
referência do blob| DB
APP -->|CMK wrap| KV
SA --> LOG
SA --> DEF
SA --> CF
LOG --> LA
DEF --> LA
CF --> LA
LA --> ALO diagrama lê-se por camadas de responsabilidade. O cliente nunca acessa o storage diretamente: a requisição chega pelo Front Door, que aplica WAF e proteção DDoS antes de qualquer coisa. O backend não transmite bytes do PDF: autentica via Managed Identity, consulta o banco para verificar se aquele cliente tem direito ao boleto solicitado, gera o SAS temporário e devolve a URL. O cliente faz o download do blob direto do storage usando esse SAS, sem o backend participar da transferência de dados. O storage só responde dentro da VNet pelo Private Endpoint, com o endpoint público desabilitado. Tudo que acontece no storage é registrado em tempo real pelo Diagnostic Settings, Defender e Change Feed, que alimentam o Log Analytics para consultas e alertas.
Quando simplificar faz sentido
Tudo que descrevi acima tem uma premissa explícita: sistema financeiro ou regulado, com escala média a grande, equipe operacional madura, e exigência de conformidade real. Se você está construindo um MVP de uma fintech ainda buscando product-market-fit, nem todas essas camadas fazem sentido no dia um, e tentar implementar tudo de uma vez vai matar o projeto antes de ele começar a entregar valor. Por outro lado, deixar todas as camadas para depois também não funciona, porque algumas decisões iniciais ficam difíceis de reverter quando o sistema já está em produção com dados reais.
O critério prático para decidir o que adicionar quando é separar entre custo de adicionar agora versus custo de adicionar depois.
Camadas com custo zero ou baixo agora e custo alto depois entram desde o dia um. Managed Identity em vez de Shared Key tem custo zero, mesma complexidade de implementação, e evita ter que migrar autenticação inteira no futuro depois que dezenas de aplicações já usam Shared Key. HTTPS obrigatório é uma checkbox, mas voltar para todos os clientes pedindo para mudar de HTTP é um projeto. Banco de dados para metadados desde o início é o mesmo trabalho que armazenar tudo em blob, e evita ter que fazer migração de dados depois com sistema rodando. SAS com validade curta é a configuração default que se adota, e se o time se acostuma a SAS de 15 minutos, nunca vai propor um de meses. Soft Delete habilitado com 30 dias de retenção custa centavos a mais e te salva da primeira DELETE FROM por engano.
Camadas com custo alto agora mas com clara janela de adicionar depois podem esperar até a janela aparecer. Private Endpoint exige planejamento de VNet, subnets, DNS e custa instâncias rodando. Faz sentido quando o produto sai do MVP e entra em produção com dados reais. Lifecycle Management é fácil de aplicar depois quando a fatura começar a crescer e ficar visível no Cost Management. Defender for Storage é um interruptor, pode ligar quando o time conseguir consumir os alertas sem se afogar.
Camadas com custo alto e específico para conformidade entram quando a conformidade entra. WORM travado faz sentido quando o produto vira regulado pelo Bacen, pela CVM ou similar. CMK faz sentido quando aparecer requisito de auditoria explícito sobre controle de chaves, ou quando algum cliente enterprise exigir no contrato. Antes disso, MMK (Microsoft-Managed Key) atende perfeitamente.
A pior decisão é overengineering antecipado, com cinco pessoas tentando implementar arquitetura de banco regulado em produto que ainda não tem usuário. A segunda pior decisão é underengineering que vira dívida técnica urgente no pior momento possível, que costuma ser logo depois que o produto começa a ir bem, e a equipe não tem tempo para refazer. O equilíbrio é começar com o mínimo defensável e ter um mapa claro do que adicionar a cada estágio do produto.
Conclusão: o que fica desta jornada
O ponto de chegada desse percurso vai além do conjunto de features ativas no storage. O que muda, depois de percorrer as camadas com o porquê de cada uma, é a forma de enxergar uma arquitetura.
Antes desse percurso, uma Storage Account com connection string parecia suficiente. Depois dele, a cadeia entre uma chave de conta vazada e execução remota de código em outras partes da infraestrutura fica visível, documentada pela Orca Security com passo a passo técnico verificável. A cadeia entre um Lifecycle mal configurado e dado pessoal acumulado por anos além do prazo legal fica visível. A cadeia entre um SAS sem escopo restrito e um token Account com trinta anos de validade publicado num repositório público fica visível, documentada pela Wiz Research com os 38TB da Microsoft.
Essa visibilidade não vem de decorar features. Vem de entender o modelo de ameaça por trás de cada camada e o princípio legal por trás de cada decisão de retenção. Um atacante que comprometer uma Managed Identity bem configurada chega num token com escopo restrito ao container de boletos e validade de uma hora. Um atacante que comprometer uma Shared Key num ambiente sem as proteções desse texto chega num acesso administrativo completo à conta, com capacidade de escalar para outros serviços do ambiente, conforme documentado pela Orca Security.
A diferença entre esses dois cenários é o que justifica cada camada adicionada ao longo do texto.
Cada escolha de segurança cobra um preço em outro pilar. CMK aumenta segurança e reduz excelência operacional, porque introduz uma dependência crítica no Key Vault com soft delete, purge protection e rotação a gerir. WORM aumenta segurança e reduz otimização de custo, porque obriga a empresa a pagar armazenamento pelo prazo travado. Private Endpoint aumenta segurança e reduz eficiência de performance, porque adiciona um salto de rede e exige resolução DNS interna correta. A arquitetura aqui descrita aceita esses trade-offs porque o caso de uso, boleto bancário em ambiente regulado, impõe esses requisitos.
Fontes e referências
As fontes abaixo são verificáveis e têm links diretos para documentação ou pesquisa citada no texto. Recomendo a leitura, especialmente da documentação do Microsoft Learn sobre Storage e dos blogs da Wiz e da Orca, que mostram cenários reais com impacto documentado.
Shared Key e por que evitar:
- Microsoft Learn, Manage account access keys: https://learn.microsoft.com/en-us/azure/storage/common/storage-account-keys-manage
- Microsoft Learn, Prevent Shared Key authorization for an Azure Storage account: https://learn.microsoft.com/en-us/azure/storage/common/shared-key-authorization-prevent
- Orca Security, From listKeys to Glory: https://orca.security/resources/blog/azure-shared-key-authorization-exploitation/
- The Register, Miscreants could use Azure access keys as backdoors: https://www.theregister.com/2023/04/11/orca_azure_access_keys/
SAS tokens e o incidente dos 38TB:
- Microsoft Learn, Grant limited access to data with shared access signatures: https://learn.microsoft.com/en-us/azure/storage/common/storage-sas-overview
- Microsoft Learn, Create a user delegation SAS: https://learn.microsoft.com/en-us/rest/api/storageservices/create-user-delegation-sas
- Microsoft Learn, Create a service SAS: https://learn.microsoft.com/en-us/rest/api/storageservices/create-service-sas
- MSRC Blog, Microsoft mitigated exposure of internal information in a storage account due to overly-permissive SAS token: https://msrc.microsoft.com/blog/2023/09/microsoft-mitigated-exposure-of-internal-information-in-a-storage-account-due-to-overly-permissive-sas-token/
- Wiz Research, 38TB of data accidentally exposed by Microsoft AI researchers: https://www.wiz.io/blog/38-terabytes-of-private-data-accidentally-exposed-by-microsoft-ai-researchers
Managed Identity e autenticação Java:
- Microsoft Learn, Authenticate Azure-hosted Java apps by using a system-assigned managed identity: https://learn.microsoft.com/en-us/azure/developer/java/sdk/authentication/system-assigned-managed-identity
- Microsoft Learn, Authorize access to blobs using Microsoft Entra ID: https://learn.microsoft.com/en-us/azure/storage/blobs/authorize-access-azure-active-directory
- Microsoft Learn, Get started with Azure Blob Storage client library for Java: https://learn.microsoft.com/en-us/azure/storage/blobs/storage-blob-java-get-started
- Microsoft Learn, Authenticate Java apps to Azure services: https://learn.microsoft.com/en-us/azure/developer/java/sdk/authentication/overview
Lifecycle Management:
- Microsoft Learn, Azure Blob Storage lifecycle management overview: https://learn.microsoft.com/en-us/azure/storage/blobs/lifecycle-management-overview
- Microsoft Learn, Lifecycle management policies that delete blobs: https://learn.microsoft.com/en-us/azure/storage/blobs/lifecycle-management-policy-delete
- Microsoft Learn, Azure Blob Storage lifecycle management policy structure: https://learn.microsoft.com/en-us/azure/storage/blobs/lifecycle-management-policy-structure
Soft Delete, Versionamento e Point-in-Time Restore:
- Microsoft Learn, Soft delete for blobs: https://learn.microsoft.com/en-us/azure/storage/blobs/soft-delete-blob-overview
- Microsoft Learn, Soft delete for containers: https://learn.microsoft.com/en-us/azure/storage/blobs/soft-delete-container-overview
- Microsoft Learn, Blob versioning: https://learn.microsoft.com/en-us/azure/storage/blobs/versioning-overview
- Microsoft Learn, Point-in-time restore for block blobs: https://learn.microsoft.com/en-us/azure/storage/blobs/point-in-time-restore-overview
- SingleStore Blog, Lessons Learned From Using Azure Versioning and Soft-Delete: https://www.singlestore.com/blog/lessons-learned-from-using-azure-versioning-and-soft-delete/
Imutabilidade WORM:
- Microsoft Learn, Overview of immutable storage for blob data: https://learn.microsoft.com/en-us/azure/storage/blobs/immutable-storage-overview
- Microsoft Learn, Container-level WORM policies for immutable blob data: https://learn.microsoft.com/en-us/azure/storage/blobs/immutable-container-level-worm-policies
- Microsoft Learn, Version-level WORM policies for immutable blob data: https://learn.microsoft.com/en-us/azure/storage/blobs/immutable-version-level-worm-policies
- OneUptime, How to Configure Immutable Storage with WORM Policies: https://oneuptime.com/blog/post/2026-02-16-how-to-configure-immutable-storage-worm-policies-azure-blob/view
Rede e Private Endpoints:
- Microsoft Learn, Use private endpoints for Azure Storage: https://learn.microsoft.com/en-us/azure/storage/common/storage-private-endpoints
- Microsoft Learn, Azure Storage firewall rules: https://learn.microsoft.com/en-us/azure/storage/common/storage-network-security
- Microsoft Learn, Azure Storage Network security overview: https://learn.microsoft.com/en-us/azure/storage/common/storage-network-security-overview
Criptografia em repouso e em trânsito:
- Microsoft Learn, Azure Storage encryption for data at rest: https://learn.microsoft.com/en-us/azure/storage/common/storage-service-encryption
- Microsoft Learn, Customer-managed keys for account encryption: https://learn.microsoft.com/en-us/azure/storage/common/customer-managed-keys-overview
- Microsoft Learn, Azure data encryption at rest: https://learn.microsoft.com/en-us/azure/security/fundamentals/encryption-atrest
Well-Architected Framework:
- Microsoft Learn, Azure Well-Architected Framework: https://learn.microsoft.com/en-us/azure/well-architected/
- Microsoft Learn, Architecture Best Practices for Azure Blob Storage: https://learn.microsoft.com/en-us/azure/well-architected/service-guides/azure-blob-storage
- Microsoft Learn, Microsoft Azure Well-Architected Framework pillars: https://learn.microsoft.com/en-us/azure/well-architected/pillars
OWASP API Security:
- OWASP, OWASP Top 10 API Security Risks 2023: https://owasp.org/API-Security/editions/2023/en/0x11-t10/
- OWASP, API1:2023 Broken Object Level Authorization: https://owasp.org/API-Security/editions/2023/en/0xa1-broken-object-level-authorization/
- OWASP, API2:2023 Broken Authentication: https://owasp.org/API-Security/editions/2023/en/0xa2-broken-authentication/
- Microsoft Learn, Mitigate OWASP API security top 10 in Azure API Management: https://learn.microsoft.com/en-us/azure/api-management/mitigate-owasp-api-threats
- Wiz Academy, OWASP API Security Top 10 Risks: https://www.wiz.io/academy/api-security/owasp-api-security
LGPD e proteção de dados:
- Lei nº 13.709/2018 (LGPD), texto integral: https://www.planalto.gov.br/ccivil_03/_ato2015-2018/2018/lei/l13709.htm
- Autoridade Nacional de Proteção de Dados (ANPD), Guia de Segurança da Informação para Agentes de Tratamento: https://www.gov.br/anpd/pt-br/documentos-e-publicacoes/guia-de-seguranca-da-informacao-para-agentes-de-tratamento-de-pequeno-porte.pdf
- ANPD, Comunicação de Incidente de Segurança: https://www.gov.br/anpd/pt-br/canais_atendimento/agente-de-tratamento/comunicado-de-incidente-de-seguranca-cis
- Microsoft, Brazil Data Protection (LGPD) compliance: https://learn.microsoft.com/en-us/compliance/regulatory/offering-lgpd-brazil
